AI algorithms are in the air. The success of those algorithms is largely attributed to dimension expansions, which makes it important for us to consider that aspect.
Matrix multiplication can be beneficially perceived as a way to expand the dimension. We begin with a brief discussion on PCA. Since PCA is predominantly used for reducing dimensions, and since you are familiar with PCA already, it serves as a good springboard by way of a contrasting example for dimension expansion. Afterwards we show some basic algebra via code, and conclude with a citation that provides the intuition for the reason dimension expansion is so essential.
From dimension reduction to dimension expansion
PCA is used for dimension reduction. The factors in PCA are simply linear combinations of the original variables. It is explained here. For a data matrix  you will have
you will have  such linear combinations. Typically we use less than because the whole point is to reduce the dimension. The resulting factors, linear transformations, are often called rotations. They are called rotations because the original data is being “rotated” such that the factors/vectors points in the direction of the maximum variance. The transforming/rotating matrix is the matrix of the eigenvectors.
such linear combinations. Typically we use less than because the whole point is to reduce the dimension. The resulting factors, linear transformations, are often called rotations. They are called rotations because the original data is being “rotated” such that the factors/vectors points in the direction of the maximum variance. The transforming/rotating matrix is the matrix of the eigenvectors.
So, when you have a matrix (in PCA that’s the column-bind eigenvectors) and you multiply it with another matrix (in PCA that’s the original data), you effectively transform the data, and linearly so. In PCA we do that so as to reduce the dimension, using less than transformations. Also, we use the eigenvector matrix as the transforming matrix (reason is not important for us now).
Moving to dimension expansion, let’s relax those two: (1) We will not use the eigenvector matrix, and (2) we can use a larger-dimension transforming matrix. Therefore the result will be of higher dimension than the original input.
I write ‘we can’ but in truth we must. The ability to transform the original data, expand it, and project to higher dimensions is a BIG part of the success of deep, large, and deep and large ML algorithms; especially those flush and heavy LLMs which are popping out left and right.
A simple magnification
Look at the following super-simple piece of code:
> A <- 10*matrix(runif(12), nrow = 4, ncol = 3) %>% round(digits= 1)
> A
[,1] [,2] [,3]
[1,] 9 4 7
[2,] 6 0 9
[3,] 9 1 7
[4,] 4 5 3
> B <- 10*matrix(runif(6), nrow = 3, ncol = 2) %>% round(digits=1)
> B
[,1] [,2]
[1,] 1 9
[2,] 8 7
[3,] 10 9
>
> transformed_B <- A %*% B
> A %*% B[,1]
[,1]
[1,] 111
[2,] 96
[3,] 87
[4,] 74
> A %*% B[,2]
[,1]
[1,] 172
[2,] 135
[3,] 151
[4,] 98
> transformed_B
[,1] [,2]
[1,] 111 172
[2,] 96 135
[3,] 87 151
[4,] 74 98
What you see is that A transforms each vector from B separately and the result is simply column-bind. Therefore we continue our talk only using one vector.
Now this following piece of code reminds us what is the meaning of matrix multiplication.
> transformed_vectors1 <- A %*% B[,1]
> sum(B[,1] * A[1,])
[1] 111
> sum(B[,1] * A[2,])
[1] 96
> sum(B[,1] * A[3,])
[1] 87
> sum(B[,1] * A[4,])
[1] 74
> transformed_vectors1
[,1]
[1,] 111
[2,] 96
[3,] 87
[4,] 74
So the result of the transformation is the sum of the element-wise rows of A times the vector. The entries of the transformed vector are a linear combination of that vector, with the combination given by the rows of A.
Note we have created more linear transformations from our original matrix (B) than its original size (was 3 by 2 and became 4 by 2). Geometrically speaking, we projected our matrix onto a higher dimensional space.
The combination themselves are given here, unlike as in PCA, by an arbitrarily chosen numbers (the entries of A). You do well to relate it to the colossal number of parameters (billions..) backing current AI algorithms. Think of those entries of A as weights/parameters which are randomly initialized, and later optimized towards values which create useful transformations for prediction purposes.
In fact, it turns out that it’s useful paramount to over-over-over-expand the dimension. Such a “let’s over-parametrize this problem” approach creates a enormous number of such transformations. While most transformations are totally redundant, some transformations are useful almost from their get-go randomized initialization (and become more useful after optimizing).
You don’t need to take my word for it
A paper titled What is Hidden in a Randomly Weighted Neural Network forcefully exemplify that point:
.. within a sufficiently overparameterized neural network with random weights (e.g. at initialization), there exists a subnet-work that achieves competitive accuracy. Specifically, the test accuracy of the subnetwork is able to match the accuracy of a trained network with the same number of parameters.
As an illustration, take a look at the first figure in that paper:
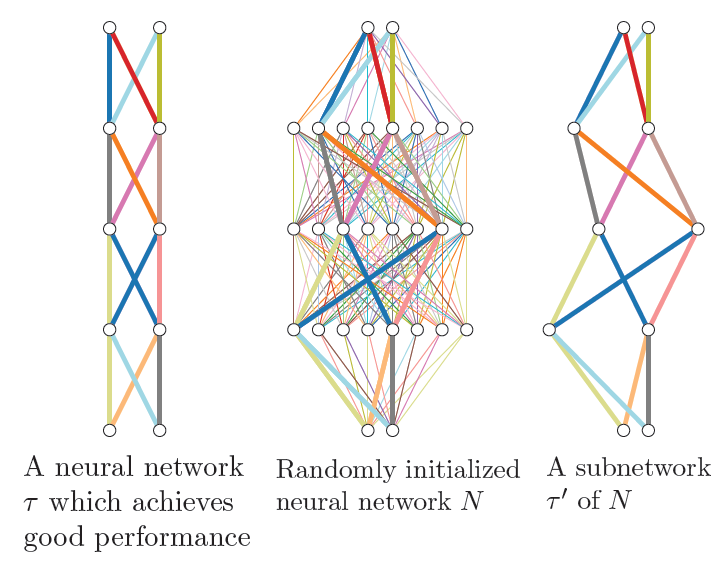 If you introduce enough expansions as in the middle panel, there will be a sub-network as in the right panel, which achieve good performance similar to that of a well-trained network as in the left panel, without ever modifying the initially randomized weight values. This figure reminds me of the saying
If you introduce enough expansions as in the middle panel, there will be a sub-network as in the right panel, which achieve good performance similar to that of a well-trained network as in the left panel, without ever modifying the initially randomized weight values. This figure reminds me of the saying If you throw enough shit against a wall, some of it has gotta stick
[pardon my french].







