Nonstandard errors is the title given to a recent published paper in the prestigious Journal of Finance by more than 350 authors. At first glance the paper appears to mix apples and oranges. At second glance, it still looks that way. To be clear, the paper is mostly what you expect from a top journal: stimulating, thought-provoking and impressive. However, my main reservation is with its conclusion and recommendations which are off the mark, I think.
I begin with a brief explanation about the content and some results from the paper, and then I share my own interpretation and perspective for what it’s worth.
What are nonstandard errors?
Say you hire two research teams to test the efficacy of a drug. You provide them with the same data. Later the two teams return with their results. Each team reports their estimated probability that the drug is effective, and the (standard) standard error for their estimate. But, since the two teams made different decisions along the way (e.g. how to normalize the data) their estimates are different. So there is additional (nonstandard) error because their estimates are not identical, despite being asked the exact same question and being given the exact same data. As the authors write: this “type of error can be thought of as erratic as opposed to erroneous”. So that is simply extra variation stemming from the teams’ distinct analytical choices (e.g. how to treat outliers, how to impute missing values).
Things I love about the paper
- Exceptional clarity, and phenomenal design-thinking.
- The logistical orchestration of bringing together over 350 people in a structured way is really not something to be jealous of. I can only imagine the headache it gives. This elevates the paper to have remarkable power. Both as an example that such large scale collaboration is actually possible, and of course the valuable data and evidence.
- On the content side, the paper brilliantly alerts the readers to be aware that results of any research are highly dependent on the decision path chosen by the research team (e.g. which model, which optimization algorithm, which frequency to choose). Results and decision-path go beyond basic dependency – there’s a profound reliance at play. This is true for theoretical work (“under assumptions 1-5…”), you can double the force for empirical studies, and in my view you can triple the force for empirical social sciences work. Below is the point estimate and distribution around 6 different hypotheses which 164 research teams were asked to test (again, using the same data). Setting aside the hypotheses’ details for now, you can see below that there is a sizable variation around the point estimates.
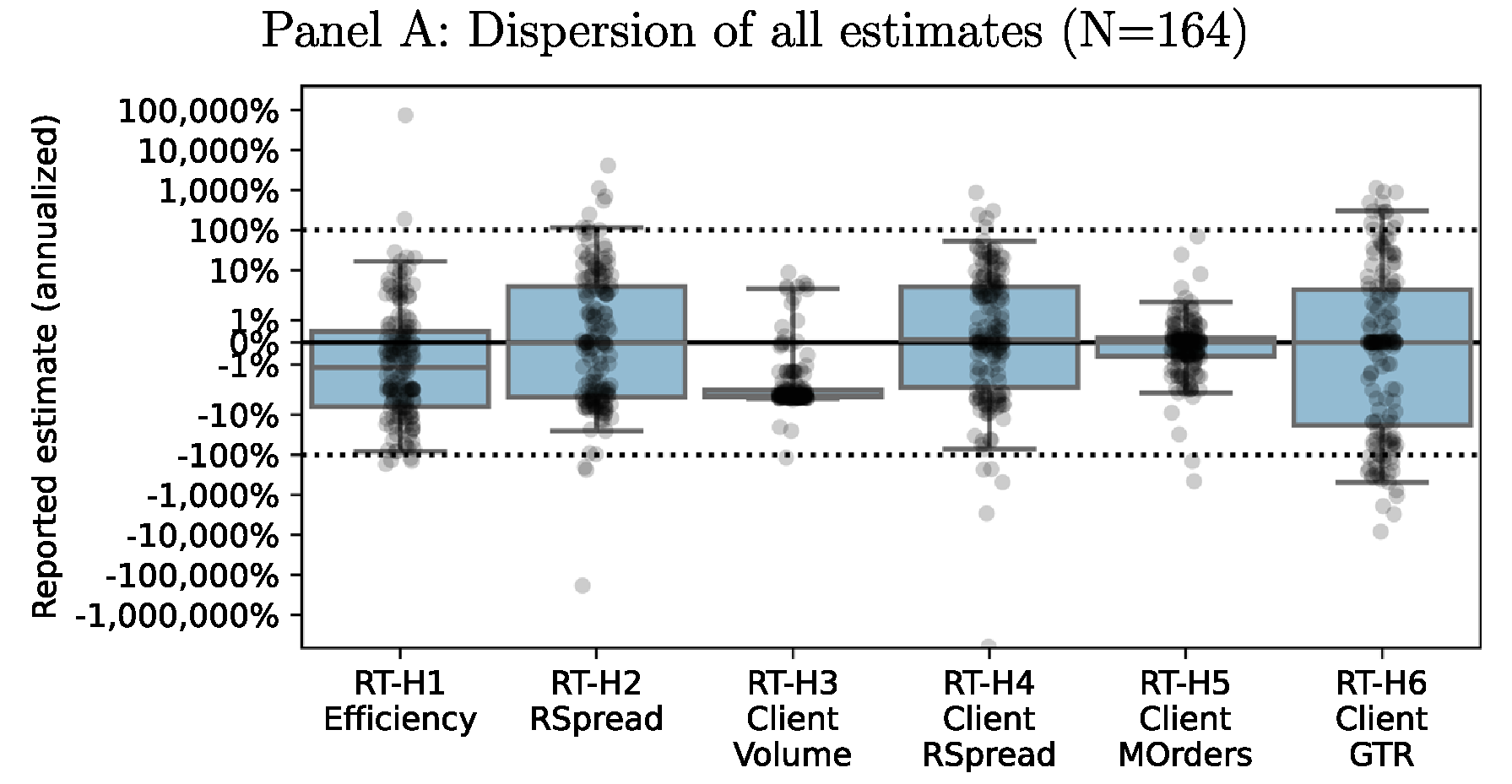
Not only the extent of the variation is eyebrows-raising, but in most cases there is not even an agreement on the sign…The paper dives deeper. Few more insights are that if we check only top research teams (setting aside now how “top” is actually determined) situation is a bit better. Also, when you asked the researchers what is their estimate for the across-teams variation they tend to underestimate it.
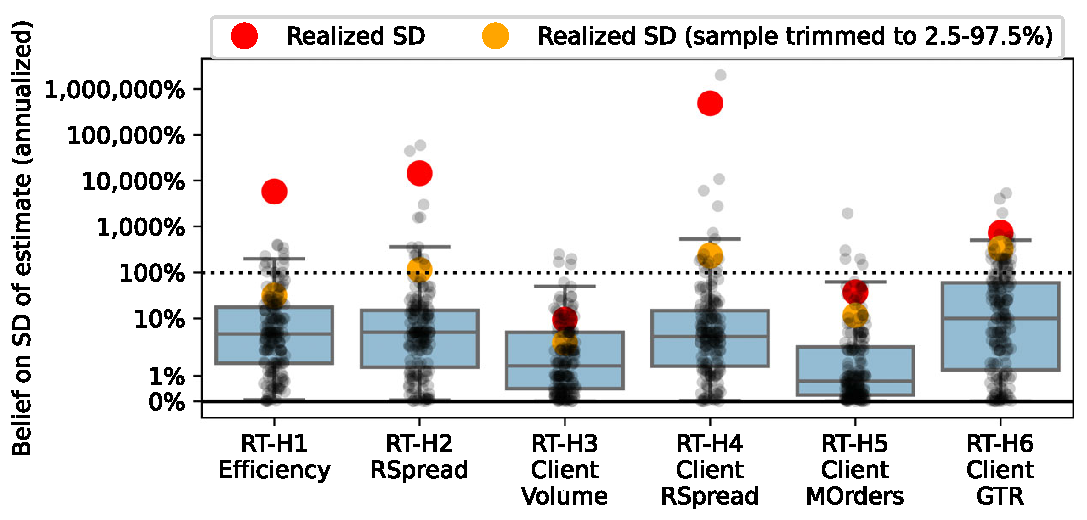
What you see is that most research teams underestimate the actual variation (black dots under the big orange dot) and that is true for all 6 hypotheses tested. This very much echos Deniel Kahneman work: “We are prone to overestimate how much we understand about the world”. - What is the main contributor for the dispersion of estimates? You guessed it, the statistical model chosen by the researchers.
Things I don’t like about the paper
The authors claim that the extra decision-path induced variation adds uncertainty, and that this is undesirable. Because of that a better approach, the claim, would be to perfectly aligned on the decision-path.
6 months ago I made a linkedin comment about the paper based on a short 2-minutes video.

Yes, it took 6 months but I now feel after reading it through that my flat “shooting from the hip” comment is still valid (although I regret the language I chose).
In the main, any research paper is, and if not then it should be, read as a stand-alone input for our overall understanding. I think it’s clear to everyone that what they read is true, conditional on what they read was done.
It’s not that I don’t mind to read that a certain hypothesis is true if, say, checked using daily frequency but is reversed if checked using monthly frequency, I WANT to read that. Then I want to read why they made the decision they made, and to make up my own mind and relate it to what I need it for in my own context.
Do we want to dictate a single procedure for each hypothesis? It is certainly appealing. We would have an easier time pursuing the truth, one work (where the decision path is decided upon) for one hypothesis, and we will have no uncertainty and no across-researchers variation. But the big BUT is this, even in the words of the authors of the same paper: “there simply is no right path in an absolute sense”. The move to a fully-aligned single procedure boils down to a risk transfer. Rather than having a risk of a researchers taking wrong turns on their decision paths (or even p-hacking), we now carry another, higher risk in my opinion, that our aligned procedure is wrong for all researchers. So, the uncertainty is still there, but now under the rag. That is even more worrisome than the across-researchers variation we CAN observe.
While I commend the scientific pursuit for truth, there isn’t always one truth to uncover. Everything is a process. In the past stuttering was treated by placing pebbles in the mouth. More recently (and maybe even still) university courses in economics excluded negative interest rates on the ground that everyone would hold cash. When time came, it turns out that there are not enough mattresses.
Across-researchers variation is actually something you want. If it’s small it means the problem is not hard enough (everyone agrees on how to check it). So, should we just ignore across-researchers variation? also not. Going back to my opening point, the paper brilliantly captures the scale of this variation. Just be ultra aware that two research-teams are not checking one thing (even if working on the same data and testing for the same hypothesis), but they are checking two things. The same hypothesis but based on particular analytical choices which they made. We have it harder in that we need to consume more research outputs, but that is a small price compared to the alternative.
Footnote
While reading the paper I thought it would be good to sometimes report a trimmed standard deviations, because of the sensitivity of that measure to outliers.







