False Discovery Rate is an unintuitive name for a very intuitive statistical concept. The math involved is as elegant as possible. Still, it is not an easy concept to actually understand. Hence i thought it would be a good idea to write this short tutorial.
We reviewed this important topic in the past, here as one of three Present-day great statistical discoveries, here in the context of backtesting trading strategies, and here in the context of scientific publishing. This post target the casual reader, explaining the concept of False Discovery Rate in plain words.
Contents
False Discovery Rate
If you have only the one hypothesis to test, if a specific trading strategy is profitable say, assuming normality (currently or at the limit) and if the hypothesis is actually null (the strategy is not profitable) then you have 5% chance of making a mistake of the first kind: deciding to reject, meaning to implement strategy which would lose money. Mistake since the hypothesis is actually null, you rejected – falsely, you ‘discovered’ something which is not there. Hence the first two words: False Discovery.
Now, say you have 1000 money managers to choose from. Testing one of them, you have a 5% chance for the following mistake: you decide that she\he is good while in fact false. Testing 10 money managers you have much, much higher, chance to err and give your money to a random walker: 40% chance to be exact. If you want to keep the chance at 5%, without it climbing to 40%, we say you want to control the family-wise error rate. One way to do that is to decide that a manager is talented only if her\his t-stat makes the cut. Not the 5% cut (t-stat=1.65) but the 5%/10= 0.5% cut (t-stat= 2.58).
Testing 1000 money managers or 1000 trading strategies.. can you spot the issue here? you would need a super-duper manager with t-stat of 5%/1000= 0.005% (t-stat of about 4) to make the cut. By moving from 1.65 to 4 we control the family-wise error at rate at 5%. Moving this threshold is key and we will get back to this in a minute. This is a very conservative approach, there are ways to be less stringent while still controlling the family-wise error rate, those are beyond the scope here.
Let’s loosen up the conditions a bit.
Let’s allow some managers which are not talented to slip through our radar. Why would you want to do this? Good question. More power is the answer. Doing this gives us more power to discover talented managers; managers who are only super (without the duper) talented.
How many managers are we willing to let under the radar? Well, that depends on what we get for it! Are we ok with splitting our money between two managers, one talented and one random walking? that would mean that we would like to control the False discovery at a rate of half; one false (random walk), but we get one true (discover a talented manager). Sounds ok? absolutely not. I am willing to give my money to a random-walker only if I discover 4 talented managers in return. Statistically put: I want to keep my False Discoveries to 20% rate, one bad apple for every 4 juicy apples.
The 1995 paper (reference below) tells us how to do that. It is not easy. For the Family-Wise Error Rate the threshold was dependent only on how many managers we tested. Now the threshold depends on how many managers we test, but not only. The threshold also depends on “what we get”, how many true discoveries we get for each bad managers we allocate to.
Simulated example
Getting busy, we generate 1000 individual tests, with 20 that are “real” (non-null) and 1000 – 20 = 980 which are null. Now, what Benjamini and Hochberg ingeniously came up with is an upper bound. If all 1000 are null, we still get our 20% by moving the threshold, if some of the 1000 are actually non-null, then we get even better rate. Also very important for the paper’s success, if all 1000 are null, then we know how they should be distributed: exactly normally distributed.
Now the tactic is to find that correct threshold which would give us the rate we are willing to tolerate.
TT <- 200
pp <- 1000
x <- matrix(nrow= TT, ncol= pp)
for (i in 1:pp){
x[,i] = rnorm(TT)
}
relevant <- 20
signall <- seq(0.1,1,length.out= relevant)
bet <- c( signall, rep(0, pp- relevant) )
eps <- rnorm(TT)
y = t(t(bet)%*%t(x))+eps # The real unknown model
tvals <- NULL
for (i in 1:pp){
tvals[i] = summary(lm(y~x[,i]))$coef[2,3]
}
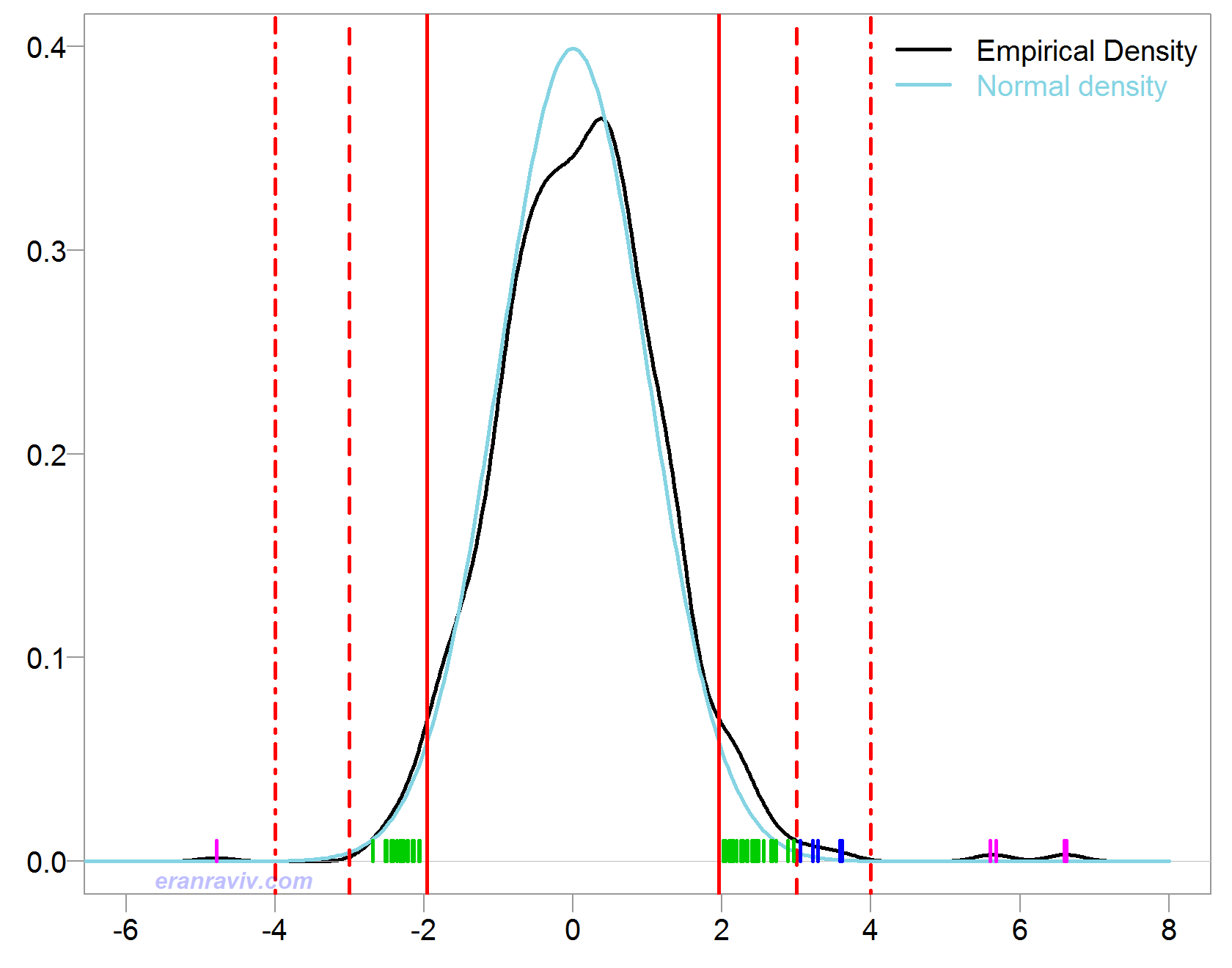
What is important? If all 1000 are null (upper bound) then, given that we get perfectly normal distribution, how many significant variables should we expect? the answer is 50 = 1000 * 0.05. How many do we have?
variables_look_interesting <- tvals[ tvals > 2 | tvals < (-2)] length(variables_look_interesting) 54
We expect 50, and we get 54. The FDR for a threshold of 2 would then be 50/54= 92.6%. That is not good. We get only four talented managers while falsely discovering 50 in return. That is much too high. Solution, increase threshold. Let’s try threshold of 3 (and 4 while we are at it):
variables_look_very_interesting <- tvals[ tvals > 3 | tvals < (-3)] variables_look_amazingly_interesting <- tvals[ tvals > 4 | tvals < (-4)]
We get 13 and 4 respectively (your result may differ due to simulation noise). For a threshold of 3 we expect .. you don’t need to look up the z-table: pp* (1-pnorm(3)) * 2 = 2.7 variables to be falsely significant (remember, under the null), but we get 13. So 2.7/13 = 20.8%. Now that is more like it. While if you compute the FDR for threshold which is 4 in the same manner, you get about 1%. The x-ticks are differently colored, corresponding to the t-stats over the different thresholds.
In this simulation we know that there are 20 variables with real effect. If we control the False Discovery at a rate of 20% we have the power to discover 13 of them. Controlling the Family-Wise Error rate, we would not risk having 2.7 false discoveries, but, we would be left with much less real discoveries. That is a tradeoff.
Additional discussion points
What guides the choice for for a particular False Discovery Rate control? In different situations we would like to control at different rates. Testing trading strategies is nothing like testing medicines or drugs which may have nasty side-effects. While we can afford a few bad apples in the former, I hope and imagine the regulator controls a very low False Discovery Rate in the latter case, a matter of preference. The explosion of interest in the False Discovery Rate and how commonplace it has become in recent years characterizes the era we are in: modern computational statistics.
Full-time modern statisticians in the academia are now busy with a deeper concept which we would not touch upon here. You made your decision: you control the False Discovery Rate by using some proper threshold, but unlike our simulation here you don’t know what is real\false. You only rely on an estimate! How good is it? what are the confidence interval around it? The False Discovery Rate estimate has non-standard distribution so it is complicated to get a feel for the uncertainty around the estimate. Just bear in mind it is only an estimate, you hope you control at the rate you want to control.
The post is math-empty, intentionally (and proudly). However, you will do well to cross this friendly introduction with the less friendly explanation from Wikipedia, where you can find also some more references and extensions.
* Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing (1995), by Yoav Benjamini and Yosef Hochberg ; A beautifully written paper, and short- an amazing #words/impact ratio. Highly recommended.








In the article you wrote the error rate is 2.7/(13 + 2.7). Shouldn’t it be 2.7/13?
Yes. Well spotted, updated.
Nice post!
Thank you.
The article is clear and bright, without any added useless details or else.
The speech is equally brilliant and vivid, so the longer I see, the longer
I really do enjoy it!