What is tail dependence really? Say the market had a red day and saw a drawdown which belongs with the 5% worst days (from now on simply call it a drawdown):
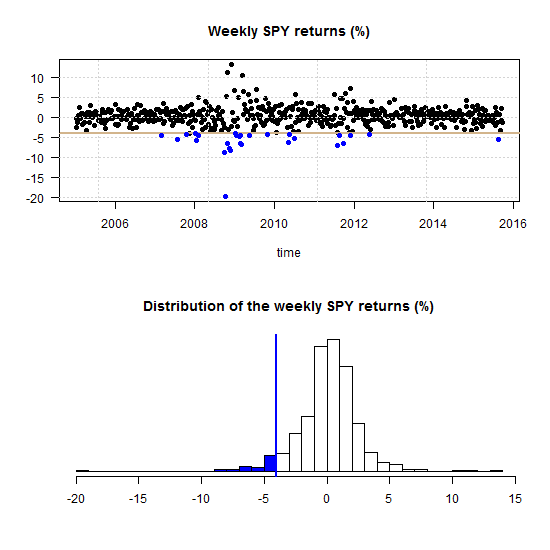
One can ask what is now, given that the market is in the blue region, the probability of a a drawdown in a specific stock?
Category: Statistics and Econometrics
Multivariate volatility forecasting (4), factor models
To be instructive, I always use very few tickers to describe how a method works (and this tutorial is no different). Most of the time is spent on methods that we can easily scale up. Even if exemplified using only say 3 tickers, a more realistic 100 or 500 is not an obstacle. But, is it really necessary to model the volatility of each ticker individually? No.
If we want to forecast the covariance matrix of all components in the Russell 2000 index we don’t leave much on the table if we model only a few underlying factors, much less than 2000.
Volatility factor models are one of those rare cases where the appeal is both theoretical and empirical. The idea is to create a few principal components and, under the reasonable assumption that they drive the bulk of comovement in the data, model those few components only.
Multivariate volatility forecasting (3), Exponentially weighted model
Broadly speaking, complex models can achieve great predictive accuracy. Nonetheless, a winner in a kaggle competition is required only to attach a code for the replication of the winning result. She is not required to teach anyone the built-in elements of his model which gives the specific edge over other competitors. In a corporation settings your manager and his manager and so forth MUST feel comfortable with the underlying model. Mumbling something like “This artificial-neural-network is obtained by using a grid search over a range of parameters and connection weights where the architecture itself is fixed beforehand…”, forget it!
Correlation and correlation structure (2), copulas
This post is about copulas and heavy tails. In a previous post we discussed the concept of correlation structure. The aim is to characterize the correlation across the distribution. Prior to the global financial crisis many investors were under the impression that they were diversified, and they were, for how things looked there and then. Alas, when things went south, correlation in the new southern regions turned out to be different\stronger than that in normal times. The hard-won diversification benefits evaporated exactly when you needed them the most. This adversity has to do with fat-tail in the joint distribution, leading to great conceptual and practical difficulties. Investors and bankers chose to swallow the blue pill, and believe they are in the nice Gaussian world, where the math is magical and elegant. Investors now take the red pill, where the math is ugly and problems abound.
Multivariate volatility forecasting, part 2 – equicorrelation
Last time we showed how to estimate a CCC and DCC volatility model. Here I describe an advancement labored by Engle and Kelly (2012) bearing the name: Dynamic equicorrelation. The idea is nice and the paper is well written.
Departing where the previous post ended, once we have (say) the DCC estimates, instead of letting the variance-covariance matrix be, we force some structure by way of averaging correlation across assets. Generally speaking, correlation estimates are greasy even without any breaks in dynamics, so I think forcing some structure is for the better.
Correlation and correlation structure (1); quantile regression
Given a constant speed, time and distance are fully correlated. Provide me with the one, and I’ll give you the other. When two variables have nothing to do with each other, we say that they are not correlated.
You wish that would be the end of it. But it is not so. As it is, things are perilously more complicated. By far the most familiar correlation concept is the Pearson’s correlation. Pearson’s correlation coefficient checks for linear dependence. Because of it, we say it is a parametric measure. It can return an actual zero even when the two variables are fully dependent on each other (link to cool chart).
Multivariate volatility forecasting (1)
Introduction
When hopping from univariate volatility forecasts to multivariate volatility forecast, we need to understand that now we have to forecast not only the univariate volatility element, which we already know how to do, but also the covariance elements, which we do not know how to do, yet. Say you have two series, then this covariance element is the off-diagonal of the 2 by 2 variance-covariance matrix. The precise term we should use is “variance-covariance matrix”, since the matrix consists of the variance elements on the diagonal and the covariance elements on the off-diagonal. But since it is very tiring to read\write “variance-covariance matrix”, it is commonly referred to as the covariance matrix, or sometimes less formally as var-covar matrix.
How regression statistics mislead experts
This post concerns a paper I came across checking the nominations for best paper published in International Journal of Forecasting (IJF) for 2012-2013. The paper bears the annoyingly irresistible title: “The illusion of predictability: How regression statistics mislead experts”, and was written by Soyer Emre and Robin Hogarth (henceforth S&H). The paper resonates another paper published in “Psychological review” (1973), by Daniel Kahneman and Amos Tversky: “On the psychology of prediction”. Despite the fact that S&H do not cite the 1973 paper, I find it highly related.
PCA as regression (2)
In a previous post on this subject, we related the loadings of the principal components (PC’s) from the singular value decomposition (SVD) to regression coefficients of the PC’s onto the X matrix. This is normal given the fact that the factors are supposed to condense the information in X, and what better way to do that than to minimize the sum of squares between a linear combination of X (the factors) to the X matrix itself. A reader was asking where does principal component regression (PCR) enter. Here we relate the PCR to the usual OLS.
Quasi-Maximum Likelihood (QML) beauty
Beauty.. really? well, beauty is in the eye of the beholder.
Yield curve forecasting
One of my Ph.D papers was published recently. It deals with yield curve forecasting.
Here is the code for applying the Nelson-Siegel model to any yield curve.
Out-of-sample data snooping
In this day and age, paralleling and mining big data, I like to think about the new complications that follow this abundance. By way of analogy, Alzheimer’s dementia is an awful condition, but we are only familiar with it since medical advances allow for higher life expectancy. Better abilities allow for new predicaments. One of those new predicament is what I call out-of-sample data snooping.
Linking backtesting with multiple testing
The other day, Harvey Campbell from Duke University gave a talk where I work. The talk- bearing the exciting name “Backtesting” was based on a paper by the same name.
The authors tackle the important problem of data-snooping; we need to account for the fact that we conducted many trials until we found a strategy (or a variable) that ‘works’. Accessible explanations can be found here and here. In this day and age, the ‘story’ behind what you are doing is more important than ever, given the things you can do using your desktop/laptop.
Mom, are we bear yet? (2)
5 weeks ago we took a look at the rising volatility in the (US) equity markets via a time-series threshold model for the VIX. The estimate suggested we are crossing (or crossed) to the more volatile regime. Here, taking somewhat different Hidden Markov Model (HMM) approach we gather more corroboration (few online references at the bottom if you are not familiar with HMM models. The word hidden since the state is ‘invisible’).
Advances in post-model-selection inference (2)
In the previous post we reviewed a way to handle the problem of inference after model selection. I recently read another related paper which goes about this complicated issues from a different angle. The paper titled ‘A significance test for the lasso’ is a real step forward in this area. The authors develop the asymptotic distribution for the coefficients, accounting for the selection step. A description of the tough problem they successfully tackle can be found here.
The usual way to test if variable (say variable j) adds value to your regression is using the F-test. We once compute the regression excluding variable j, and once including variable j. Then we compare the sum of squared errors and we know what is the distribution of the statistic, it is F, or  , depends on your initial assumptions, so F-test or -test. These are by far the most common tests to check if a variable should or should not be included. Problem arises if you search for variable j beforehand.
, depends on your initial assumptions, so F-test or -test. These are by far the most common tests to check if a variable should or should not be included. Problem arises if you search for variable j beforehand.