At least in part, a typical data-scientist is busy with forecasting and prediction. Kaggle is a platform which hosts a slew of competitions. Those who have the time, energy and know-how to combat real-life problems, are huddling together to test their talent. I highly recommend this experience. A side effect of tackling actual problems (rather than those which appear in textbooks), is that most of the time you are not at all enjoying new wonderful insights or exploring fascinating unfamiliar, ground-breaking algos. Rather, you are handling\wrangling\manipulating data, which is.. ugly and boring, but necessary and useful.
I tried my powers few years ago, and again about 6 months ago in one of those competitions called Toxic Comment Classification Challenge. Here are my thoughts on that short experience and some insight from scraping the results of that competition.
- It requires an awful lot of time to compete for a prize money.
- You shouldn’t. You better not compete for a prize money (not you of course since you are super talented, this comment is directed to all other readers). Personally speaking, there are better players out there, some are even making a living out of it. Apart from that, as explained more fully below, there is a fair amount of luck involved in actually winning a prize money.
- This is not to say that you should not compete. You should, absolutely. Hard to imagine you will regret it.
- In this particular competition, briefly, the question was how to recognize offensive comments without a human intervention (you can check the link above for more info if you are curious). That was a stimulating problem to think about. Loading, cleaning and manipulating the data was uninteresting but very useful. You simply can’t get this kind of exercise from a textbook. No one would do this to you because you will directly one-star the book (and be right to do so).
- There is a lot of learning in the first stages of your experience, you can stop after few days when the learning curve flattens. By that, you are still involved, you can enjoy the challenge, you are not disappointed when your ranking inevitably decreases, and you don’t get to the point where you need to pour very many hours for a marginal advancement.
Luck is an important ingredient for winning a Kaggle competition
After the competition ended I took a look at the data. If you have a kaggle account you can copy paste out the data. There are many data points and much to say so instead of creating the usual SVG\PNG files as I do when I want to show something, I created the below plotly graphics. You need to use controls (select, zoom, pan, hover, at the top right corner), to see better what I am referring to.
The first chart shows the score on the x-axis (higher is better) and the y-axis shows the number of entries (submissions, attempts) per participant\team.
Kaggle results (A)
The second chart is a column chart which counts how many entries per score, basically a vertical stacking of the chart above:
Kaggle results (B)
Trivially, those who realize they are completely off the mark don’t submit anymore, so you have few attempts with very low score. Those who realize they have a chance continue to try. You can see a bunch of players\teams which get stuck: they continue to submit but their score does not improve (top chart: points around 50 submissions with score < 0.98). If you zoom-in on the range [0.9862 - 0.9864] you can see it is very crowded there. The simple reason is that someone shared his\her method publicly, so many players probably tried to use that submission as a starting point and improve upon it. This is a snapshot from a kernel which was made public for everyone, and is why I suspect that score is so prevalent:
Submission which was made public
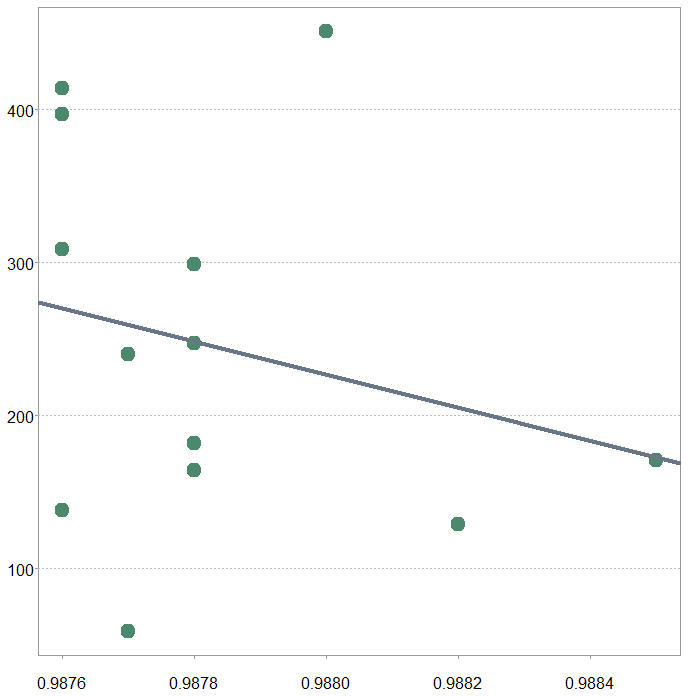
Generally speaking, if the number of entries\submissions is high, the score they achieve is better. However, if you zoom-in on those front-runners, those teams which score above say 0.987 you can observe few things. The first is that the differences are already ridiculously low. The relative ranking between teams require five decimal place accuracy there, even six at times (so 0.0000x difference can move you up or down the ladder). The second things is that the correlation breaks down. Look hard enough and you find it can become negative in some regions. Perhaps an example for what personally call out of sample data-snooping. There are teams that submit so many times, even though the evaluation is done on a hidden data, and in that sense completely out-of-sample, they manage to fit even the public part of the out-of-sample quite well. However, when it comes to a show-down, their models fail them on completely new data.
Out of sample data snooping
“The key to happiness – have low expectations” (The Telegraph, and some academic research probably). Try your powers in one of those competitions, absolutely, but don’t set your eyes on the prize-money. Set your eyes on the learning experience. In order for a competition not to drain energy and depress you, stopping quickly when the learning curve flattens is something worth considering in my opinion. More so in light of what you saw above. You can like that have more time, and be less timid entering another one.







