Frequently, we see the term ‘control variables’. The researcher introduces dozens of explanatory variables she has no interest in. This is done in order to avoid the so-called ‘Omitted Variable Bias’.
What is Omitted Variable Bias?
In general, OLS estimator has great properties, not the least important is the fact that for a finite number of observations you can faithfully retrieve the marginal effect of X on Y, that is  . This is very much not the case when you have a variable that should be included in the model but is left out. As in my previous posts about Multicollinearity and heteroskedasticity, I only try to provide the intuition since you are probably familiar with the result itself.
. This is very much not the case when you have a variable that should be included in the model but is left out. As in my previous posts about Multicollinearity and heteroskedasticity, I only try to provide the intuition since you are probably familiar with the result itself.
For illustration, consider the model

So Y is the sum, i.e.  . What happens to our estimate for
. What happens to our estimate for  when we do not include
when we do not include  in the model? Mathematically we get the simple result*:
in the model? Mathematically we get the simple result*:

The second term on the RHS is bad news.  is the estimate of the coefficient from the (hypothetical) equation
is the estimate of the coefficient from the (hypothetical) equation

In words, the term  represents the bias. It is influenced by:
represents the bias. It is influenced by:
1.
The real unknown value of  . If the real effect of on Y is absolute small, it pushes the combined term to zero and bias is small.
. If the real effect of on Y is absolute small, it pushes the combined term to zero and bias is small.
2.
How closely related are to  . This is less trivial, if the has nothing to do with and you are lucky to get the estimate to show it, the multiplicand goes to zero and bias is small. You need to be lucky since the estimate (and hence the bias) depends on the actual sample you have, you can be unlucky and get an absolute large estimate even when the X’s are independent in the population level. This subtlety can be better stated in classical textbooks.
. This is less trivial, if the has nothing to do with and you are lucky to get the estimate to show it, the multiplicand goes to zero and bias is small. You need to be lucky since the estimate (and hence the bias) depends on the actual sample you have, you can be unlucky and get an absolute large estimate even when the X’s are independent in the population level. This subtlety can be better stated in classical textbooks.
Now, why is this so? The unaccounted-for influence of on Y, pushes through anyway. Mr. tells himself that if he is out, he is going to do what he can from the outside. He talks to and depending on (as in the dry formulas), how muscular is Mr. (real value of ) and the nature of their relationship (as in 2 above), is going to accommodate with his request. If they do not know each other, i.e. correlation is zero, will ignore this harassment and the bias is unlikely to be strong.
Illustration of Omitted Variable Bias
For a couple of more important insights, I need to make an illustration:
# Help function one:
hfun1 <- function(TT = 50, niter = 100, cc){
cof_full <- cof_missing <- matrix(nrow = niter, ncol = 2)
corr <- NULL
for (i in 1:niter){
# simulate from multivariate normal:
Sim.sig <- matrix(c(1,cc,cc,1),2,2 )
Sim.x <- mvrnorm(n = TT, mu=rep(1,2), Sigma=Sim.sig)
x1 <- Sim.x[,1]
x2 <- Sim.x[,2]
corr[i] <- cor(x1,x2)
y <- x1 + x2 + rnorm(TT)
lm_full <- lm(y~x1+x2)
lm_missing <- lm(y~x1)
cof_full[i,] <- summary(lm_full)![coef[2,1:2] # Extract estimate and SD of estimate cof_missing[i,] <- summary(lm_missing)](https://eranraviv.com/wp-content/ql-cache/quicklatex.com-1b5ed7da65dca25e6ccfb67f1a6d43a2_l3.svg "Rendered by QuickLaTeX.com") coef[2,1:2]
}
list(cof_full = cof_full, cof_missing = cof_missing, correl = corr)
}
# Run this function, once with 50 observations, once with 500.
seqq1 <- seq(-.9,.9,.05)
L <- list()
Lcorrel <-Lestimate1 <- Lstd1 <-Lestimate2 <- Lstd2 <- NULL
stdestimate1 <- stdestimate2 <- stdstdestimate1 <- stdstdestimate2 <- NULL
for (i in 1:length(seqq1))
{
L[[i]] <- hfun1(TT = 500, cc = seqq1[i])
Lcorrel[i] <- mean(L[[i]]
coef[2,1:2]
}
list(cof_full = cof_full, cof_missing = cof_missing, correl = corr)
}
# Run this function, once with 50 observations, once with 500.
seqq1 <- seq(-.9,.9,.05)
L <- list()
Lcorrel <-Lestimate1 <- Lstd1 <-Lestimate2 <- Lstd2 <- NULL
stdestimate1 <- stdestimate2 <- stdstdestimate1 <- stdstdestimate2 <- NULL
for (i in 1:length(seqq1))
{
L[[i]] <- hfun1(TT = 500, cc = seqq1[i])
Lcorrel[i] <- mean(L[[i]]![correl) Lestimate1[i] <- mean(L[[i]]](https://eranraviv.com/wp-content/ql-cache/quicklatex.com-9d462e20ac41845687fa0f3b8e8a467c_l3.svg "Rendered by QuickLaTeX.com") cof_full[,1])
Lstd1[i] <- sd(L[[i]]
cof_full[,1])
Lstd1[i] <- sd(L[[i]]![cof_full[,1]) Lestimate2[i] <- mean(L[[i]]](https://eranraviv.com/wp-content/ql-cache/quicklatex.com-c6ece26a161d53883109ce189aebaa5c_l3.svg "Rendered by QuickLaTeX.com") cof_missing[,1])
Lstd2[i] <- sd(L[[i]]
cof_missing[,1])
Lstd2[i] <- sd(L[[i]]![cof_missing[,1]) stdestimate1[i] <- mean(L[[i]]](https://eranraviv.com/wp-content/ql-cache/quicklatex.com-229300e78b6bcdd302cda5d4e838dc28_l3.svg "Rendered by QuickLaTeX.com") cof_full[,2])
stdestimate2[i] <- mean(L[[i]]
cof_full[,2])
stdestimate2[i] <- mean(L[[i]]![cof_missing[,2]) stdstdestimate1[i] <- sd(L[[i]]](https://eranraviv.com/wp-content/ql-cache/quicklatex.com-b6d3f91d1a1d0f43aa95877228e2f2bd_l3.svg "Rendered by QuickLaTeX.com") cof_full[,2])
stdstdestimate2[i] <- sd(L[[i]]$cof_missing[,2])
}
cof_full[,2])
stdstdestimate2[i] <- sd(L[[i]]$cof_missing[,2])
}
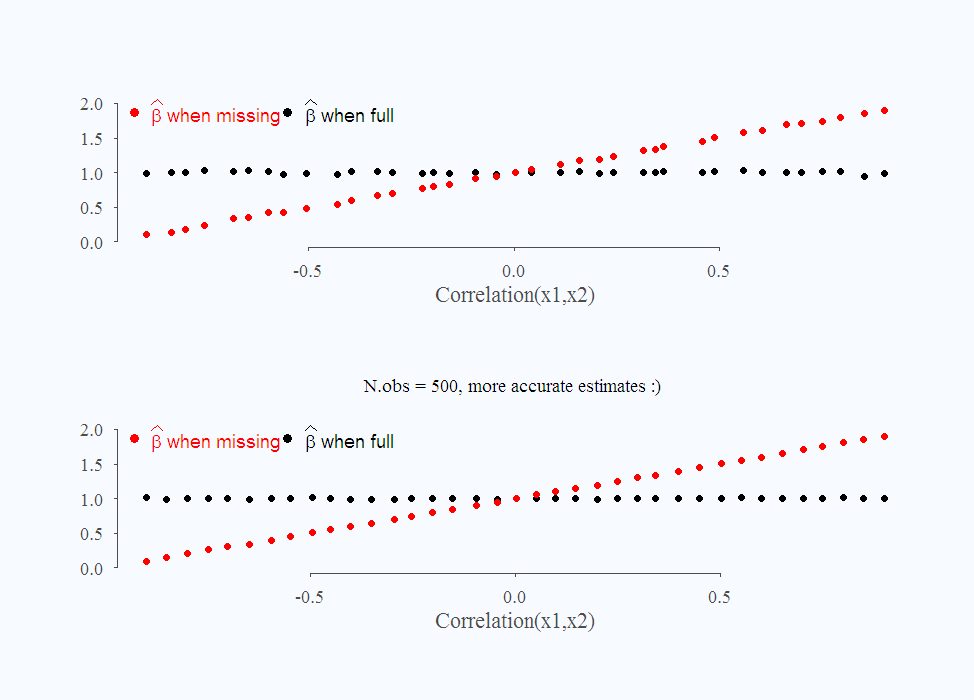
Finally, have a look at this absurd situation, I plot the standard deviation of the estimate when there is a bias and when there isn't:
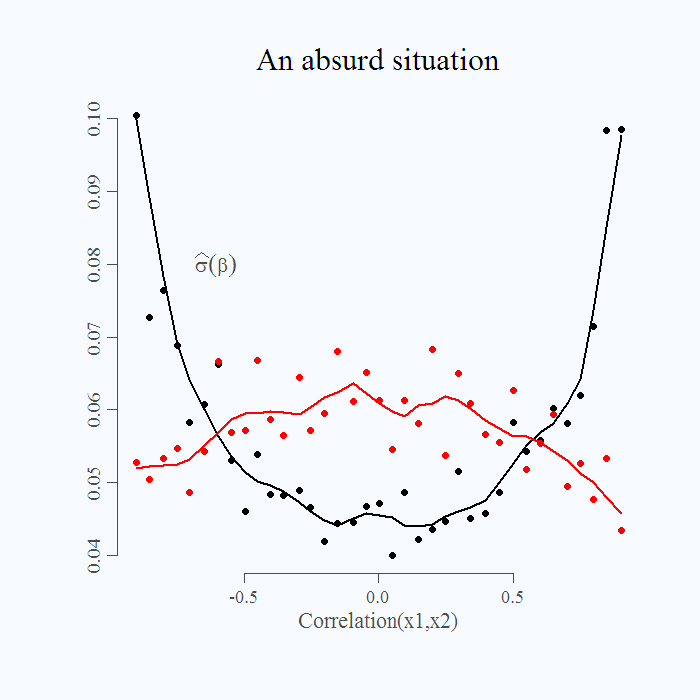
It is absurd. When the bias is small, around zero, we find it harder to estimate the parameter (standard deviation of the estimate is relatively high). On the other hand, when the bias is strong, standard deviation is lower. When the the model is more severely misspecified, we get a more accurate estimate. Talk about the dangerous inference.
* Derivation in page 149 of this book.







