Couple of months ago I published a paper in Significance – couple of pages describing the essence of deep learning algorithms, and why they are so popular. I got a few requests for the code which generated the figures in that paper. This weekend I reviewed my code and was content to see that I used a pseudorandom numbers, with a seed (as oppose to completely random numbers; without a seed). So now the figures are exactly reproducible. The actual code to produce the figures, and the figures themselves (e.g. for teaching purposes) are provided below.
library(MASS)
library(pracma)
set.seed(1212)
nn <- 100
tmpp <- mvrnorm(n = nn, mu=c(0,0), Sigma=matrix(c(1,0,0,1), nrow=2, ncol= 2),
tol = 1e-6,
empirical = FALSE, EISPACK = FALSE)
tmpp2 <- mvrnorm(n = nn, mu=c(0,0), Sigma=matrix(c(15,0,0,15), nrow=2, ncol= 2),
tol = 1e-6,
empirical = FALSE, EISPACK = FALSE)
plot(tmpp[,1], tmpp[,2], xlim= c(-10,10), ylim= c(-10,10) , pch= 19, ylab="")
points(tmpp2[,1], tmpp2[,2], xlim= c(-10,10), ylim= c(-10,10) , col= 4, pch= 19)
grid()
tmp4 <- tmp3 <- matrix(nrow= nn, ncol= 2)
for (i in 1:nn){
tmp3[i,] <- cart2pol(c(tmpp[i,]))
tmp4[i,] <- cart2pol(c(tmpp2[i,]))
}
plot(tmp3[,1], tmp3[,2], xlim= c(-4,4), ylim= c(0,13), pch= 19, ylab="")
points(tmp4[,1], tmp4[,2], col= 4, pch= 19)
abline(h= 3)
grid()
x <- rbind(tmpp,tmpp2)
y <- c(rep(0, NROW(tmpp)), rep(1, NROW(tmpp2)))
lm0 <- glm(y~x,family = binomial)
plot(x, col= (round(lm0$fit)+9), pch=19, ylab="")
grid()
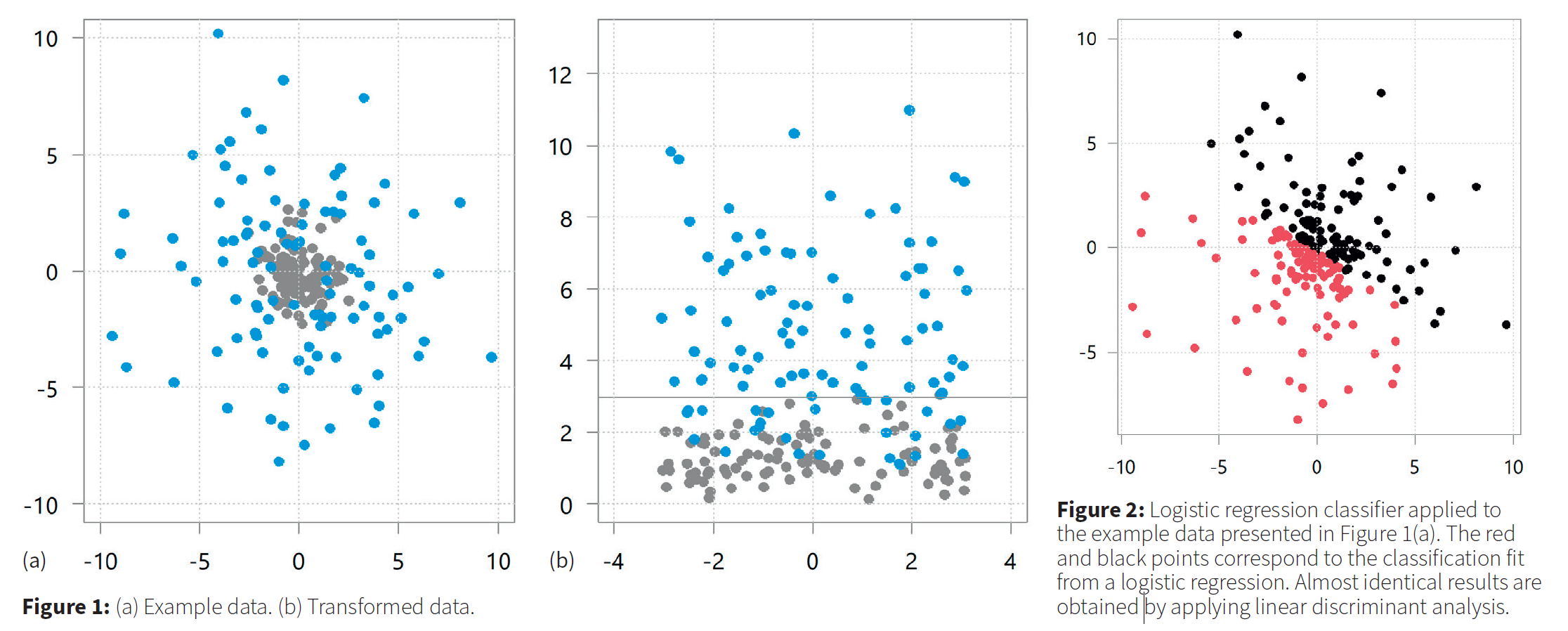
Reference: What’s the big idea? Deep learning algorithms.








Thanks for sharing this! As a note to other readers who might get misled by the usage of the term “pseudorandom” in this article: It’s not the absence of manually setting a seed that defines whether numbers are truly random or pseudorandom but whether the numbers are computationally deterministic. Base R always produces pseudorandom numbers – if one doesn’t manually set a seed, R will automatically generate one. See `?base::Random`: “Initially, there is no seed; a new one is created from the current time and the process ID when one is required.” Setting a seed manually makes the pseudorandom numbers *reproducible*, which is great. True random numbers can be obtained e.g. by using the package {random} which obtains them from RANDOM.ORG and thus from atmospheric noise.