Tree-based methods like decision trees and their powerful random forest extensions are one of the most widely used machine learning algorithms. They are easy to use and provide good forecasting performance off the cuff more or less. Another machine learning community darling is the deep learning method, particularly neural networks. These are ultra flexible algorithms with impressive forecasting performance even (and especially) in highly complex real-life environments.
This post is shares:
Over Christmas I read the following two papers long-resting in my “to-read” list:
I was pleasantly surprised to observe the synergy between the two papers, given they are published almost a decade apart. Here are couple of excerpts from the two papers.
Paper 1 compares the performance of 17 algorithm families – each family with numerous variants totaling 179 classifiers, across 121 data sets. They find that
“The classifiers most likely to be the bests are the random forest versions”
and
“the best of which are implemented in R and accessed via caret.”
Below is Figure 2 (right) from the paper which I find relevant to show here:
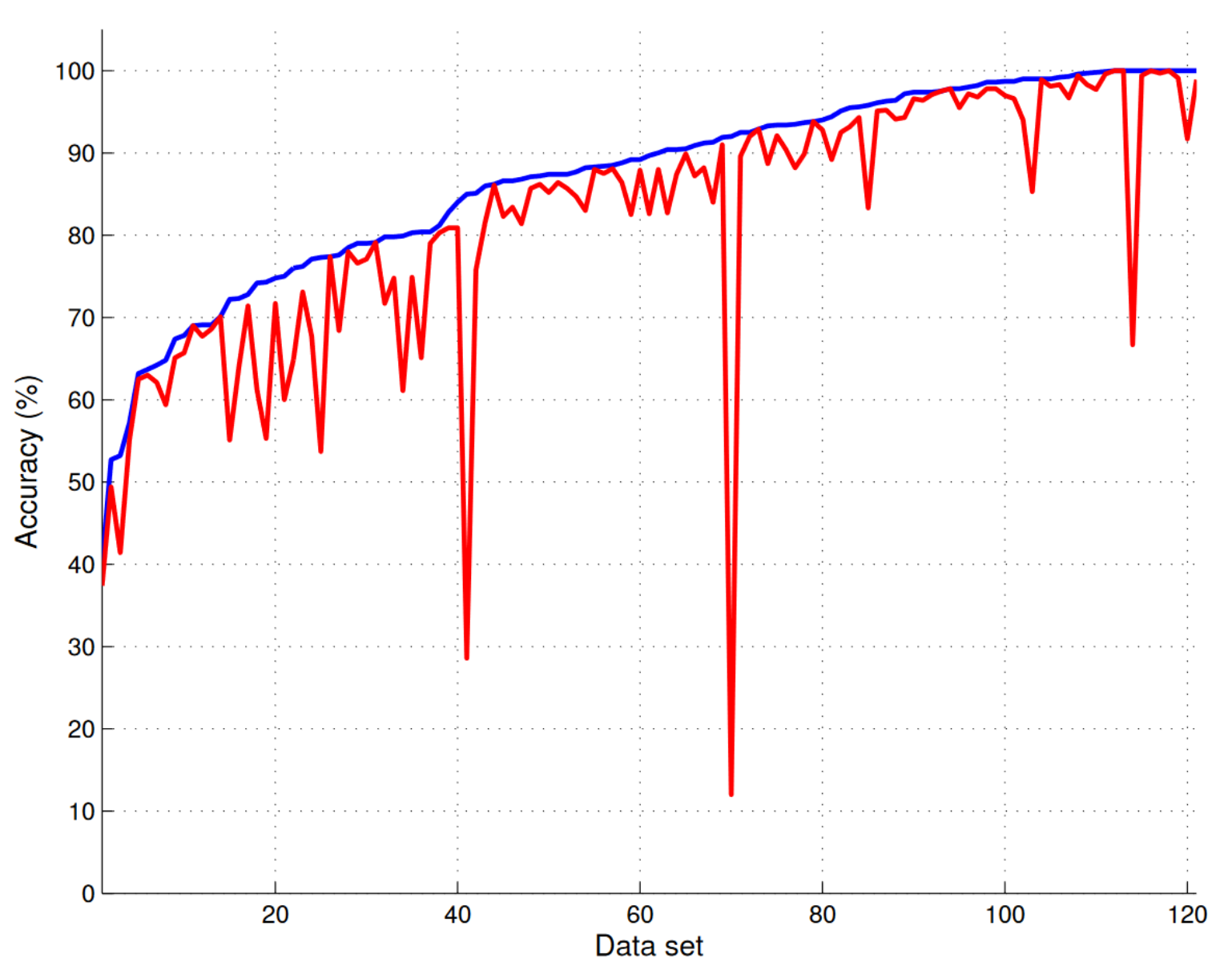 The x-axis has the different data on it (so 121 data sets). The blue line is the accuracy obtained by the best classifier. The red is the accuracy obtained by the random forest algorithm (parallel version). For almost all data the accuracy achieved by the random forest algorithm is fairly close to the best, or it is itself the best. Sure, on some data (such as data 41 and 70, see the downward spikes) it performs much worse when compared to the best classifier for that data. Still the takeaway stands: random forest is likely to do very well. Of course neural networks are no slouches and do appear in the top 10 performers in this exercise.
The x-axis has the different data on it (so 121 data sets). The blue line is the accuracy obtained by the best classifier. The red is the accuracy obtained by the random forest algorithm (parallel version). For almost all data the accuracy achieved by the random forest algorithm is fairly close to the best, or it is itself the best. Sure, on some data (such as data 41 and 70, see the downward spikes) it performs much worse when compared to the best classifier for that data. Still the takeaway stands: random forest is likely to do very well. Of course neural networks are no slouches and do appear in the top 10 performers in this exercise.
Paper 2 (by the way it’s open access so you can download the published version) is basically some shared thoughts from experienced practitioners with regards to the M5 competition – forecasting 42,840 time series. From the paper
“Our central observation is that tree-based methods can effectively and robustly be used as blackbox learners” [emphasis mine]
The winning algorithm in the M5 competition was a random forest variant. The authors make the point, and I agree, that one important difference between tree-based methods and neural network is the available at-the-ready software; tree-based methods enjoy more mature publicly available software. Mature in the sense that proper default values for hyperparameters are established, and also that they are easy to configure.
Another second point is something you may already know: “The difficulty of tuning these [neural networks] models makes published results difficult to reproduce and extend, and makes even the original investigation of such methods more of an art than a science.” (quoted from Algorithms for Hyper-Parameter Optimization). There is no way to sugar-coat it, neural networks are way much more sensitive (less robust) to hyperparameters than tree-based methods. Neural networks are also quite sensitive to feature-scaling, there is a large amount of hyperparameters to tweak, and the tweaking of many hyperparamers substantially alters expected forecasting performance. This lack of robustness makes it tedious to promise the same out-of-sample performance as the one observed for the validation set. That said, neural networks are fashionable nevertheless. Especially because of their capacity to flex themselves in order to capture complex underlying data generating process. A prominent example is the M4 competition where the winning algorithm heavily relies on neural networks.
So when to use what?
Neural networks are more flexible than tree-based methods. They can approximate any reasonable function to perfection. But as you read above, tree-based methods are likely to perform well in many cases, and with less effort. Therefore I conclude here that if the problem is not super complex, tree-based algorithms should be your go-to; they have accomplished a “good-enough” status in my mind. If the problem is complex, highly non-linear, you have enough data, you have time to fiddle with hyperparameters and sufficient computing power to do so (without waiting two weeks for the results I mean), neural networks are decidedly worth the trouble.








Random forests can also be implemented on very cheap hardware with low power consumption. Neural networks tend to be a lot more computationally expensive, especially during training.