This post is inspired by Leo Breiman’s opinion piece “No Bayesians in foxholes”. The saying “there are no atheists in foxholes” refers to the fact that if you are in the foxhole (being bombarded..), you pray! Leo’s paraphrase indicates that when complex, real problems are present, there are no Bayesian to be found.
A nice illustration for why one would prefer the Bayesian approach over the Frequentist approach is given in the wonderful book Computer age statistical inference, section 3.3.
To make the point quickly: imagine you want estimate the mean of the weight distribution for 40 years old males, and you have 10 observations (individuals). Observations are measured such that each guy stands on the scales and reports his weight. The range of results turns out to be between 75 and 95, and the average is 85. If weight is normally distributed (it is) then 85, the average, is the best estimate for the mean. However, if on the next day it turns out that the scales are faulty, specifically that anything over a weight of 100 is reported as 100, then the distribution of the observations is not normal any more (but is capped at 100). If the distribution of the sample is not normal then 85 is not the best estimate for the mean (the actual estimate should be lower than 85). So.. even though we have only the one data, which has not changed mind you, the mere fact that we found out the scales are faulty, and even though we had not a single observation over 100, our Frequentist statistician now believes she has a biased estimate for the mean. Before we discovered the problem with the scales, that estimate was optimal – perfect. Now, with no new data, only new information, the estimate is sub-optimal and must be adjusted.
In that sense Frequentist is rightly accused for being internally inconsistent with regards to the data. This is a by-product of the belief that data originates from some underlying real, yet unobserved distribution. In sharp contrast, the Bayesian believes that the one realization is it(!), nothing else could have been seen. If there is no other possible data but the one we observe, then what’s to talk about? The average of the observed data is the mean, period. Ah ha, while the Frequentist believes there is the one parameter to be estimated, the Bayesian does not. Rather, there are many possible values which would fit the data we see. The only question is which values make sense for our realized, “single truth” data. The average is indeed the most likely estimate for the mean, but we can consider other possible values via some prior distribution around the mean.
It is this business of adding another distributional layer between the problem solver and its target, be it prediction or estimation, that creates the preference for other methods. Bayesian machinery piles additional hyperparameters, often over already existing hyperparameters. I don’t see many, if at all, applications of Bayesian methodology to real data, still no.
As Prof. Efron writes in his 1986 paper “Why Isn’t Everyone a Bayesian?”:
“Bayesian theory requires a great deal of thought about the given situation to apply sensibly… All of this thinking is admirable in principle, but not necessarily in day-to-day practice.”
There are many special cases where there is a one-to-one mapping between the Bayesian and Frequenist statistician. I came up a Frequenist and so I am perhaps biased towards that paradigm, but I am not the only one who finds Frequenism to be more practical simply. For example, you may not have known that both ridge regression and lasso regression have their Bayesian counterparts. Ridge regression can be cast as bayesian regression with a Gaussian prior for the parameters, and lasso regression can be cast as a bayesian regression with Dirichlet prior for the parameters*. These facts are barely mentioned, probably because most if not all practitioners choose the Frequenist path for estimation, as also mentioned in the Computer age statistical inference book (section 7.3): “Despite the Bayesian provenance, most regularization research is carried out frequentistically” (not a typo..).
Finally, I query the google trends API for the search-term Bayesian Statistics, so as to gauge the level of interest over time (indeed, assuming number of googles is a good proxy for “interest”). Here is the result:
Google trends (smoothed) time series for the search-term “Bayesian Statistics”
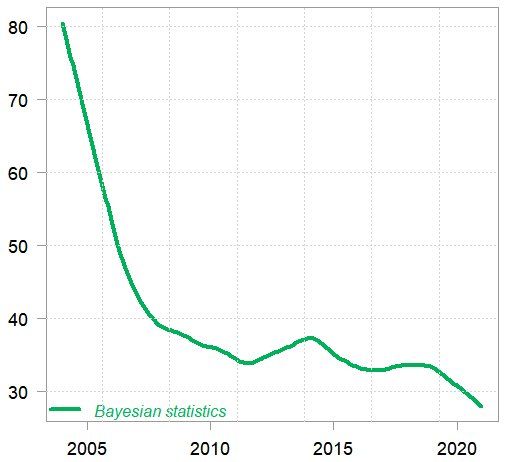
The earliest data is from 2004. Data is normalized by google, and smoothed by yours truly. A telling image.
As I wrote before: don’t be a Bayesian, nor be a Frequenist, be opportunist. I don’t have a dog in this fight, I am only making the point that intellectual curiosity alone does not justify the rivers of ink that are being spilled over Bayesian methods.
Footnotes
* See for example Dirichlet–Laplace Priors for Optimal Shrinkage









I was quite confused by your example of weighing 40 males where the scale is faulty. Censored data is very easily handled in Stan.