GARCH models are very responsive in the sense that they allow the fit of the model to adjust rather quickly with incoming observations. However, this adjustment depends on the parameters of the model, and those may not be constant. Parameters’ estimation of a GARCH process is not as quick as those of say, simple regression, especially for a multivariate case. Because of that, I think, the literature on time-varying GARCH is not yet at its full speed. This post makes the point that there is a need for such a class of models. I demonstrate this by looking at the parameters of Threshold-GARCH model (aka GJR GARCH), before and after the 2008 crisis. In addition, you can learn how to make inference on GARCH parameters without relying on asymptotic normality, i.e. using bootstrap.
Estimation of Threshold-GARCH model
If you are reading this, you probably need no preamble for a GARCH process, so we skip it (see here if you do). The Threshold-GARCH process is written as
![\[\sigma_t = \omega + \alpha \varepsilon^2_{t-1} + \gamma \mathbbm{I_{t-1}}{} \varepsilon^2_{t-1} + \beta \sigma^2_{t-1}\]](https://eranraviv.com/wp-content/ql-cache/quicklatex.com-a818c57a0abf67d6d660ad74c0e4781b_l3.svg "Rendered by QuickLaTeX.com")
where
![\[\mathbbm{I_{t-1}} = \left\{ \begin{array}{rl} 0 & \; if \quad r_{t-1} < \mu \\ 1 & \; if \quad r_{t-1} > \mu \end{array} \right.\]](https://eranraviv.com/wp-content/ql-cache/quicklatex.com-f0e6ad252b9749fee71e8448d6a23790_l3.svg "Rendered by QuickLaTeX.com")
So the additional feature of this model over the traditional GARCH is that we allow the persistence with respect to yesterday’s squared residual  based on yesterday’s return
based on yesterday’s return  , to change with the value of that return. For example, on down days we may have stronger persistence than on up days. What we call ‘up’ and ‘down’ is determined by the
, to change with the value of that return. For example, on down days we may have stronger persistence than on up days. What we call ‘up’ and ‘down’ is determined by the  parameter, which is estimated from the data, and is typically close to zero when estimated using daily returns.
parameter, which is estimated from the data, and is typically close to zero when estimated using daily returns.
Here is the code for the estimation if you want to play around with it:
library(quantmod) # http://www.quantmod.com
k <- 20 # how many years back?
end<- format(Sys.Date(),"%Y-%m-%d")
start<-format(Sys.Date() - (k*365),"%Y-%m-%d")
sym = c('SPY') # ETF which tracks S&P 500
l <- length(sym)
dat0 = as.matrix(getSymbols(sym, src="yahoo", from=start, to=end, auto.assign = F, warnings = FALSE,symbol.lookup = F))
n = NROW(dat0)
ret = dat0[2:n,4]/dat0[1:(n-1),4] - 1 # returns, close to close, percent
# plot(100*as.numeric(ret)) # uncomment to plot the returns
#--------------------------------------------
# Now we implement GJR GARCH (or threshold GARCH) for the period before and after the crisis
# Dating of crisis is found here: http://www.nber.org/cycles.html
#--------------------------------------------
before_crisis <- which(as.Date(names(dat0[,1])) == "2007-12-03")
library(rugarch) # Alexios Ghalanos (2014). rugarch: Univariate GARCH models. R package version 1.3-4.
gjrtspec <- ugarchspec(mean.model=list(armaOrder=c(1,0)),variance.model =list(model = "gjrGARCH"),distribution="std") # std is student t distribution
Tgjrmodel_Before = ugarchfit(gjrtspec, ret[1:before_crisis])
Tgjrmodel_After = ugarchfit(gjrtspec, ret[(before_crisis+1):length(ret)] )
#--------------------------------------------
# Now we plot the beta and gamma parameters
#--------------------------------------------
tempcol <- c("darkgreen", "darkkhaki")
coeftab <- cbind( coef(Tgjrmodel_Before), coef(Tgjrmodel_After))
barplot(t(coeftab[5:6,]), beside= T, names.arg= c("Before", "After"),
legend.text = colnames(t(coeftab[5:6,])),
col= tempcol, args.legend= list(bty= "n", col= tempcol, cex= 2,
text.col= tempcol) )
We have estimated Threshold-GARCH model for the period before and after the crisis using the same GARCH specification. The parameters I am interested in, are the gamma and the beta from the above equation. Here they are for the two periods, before and after the crisis:
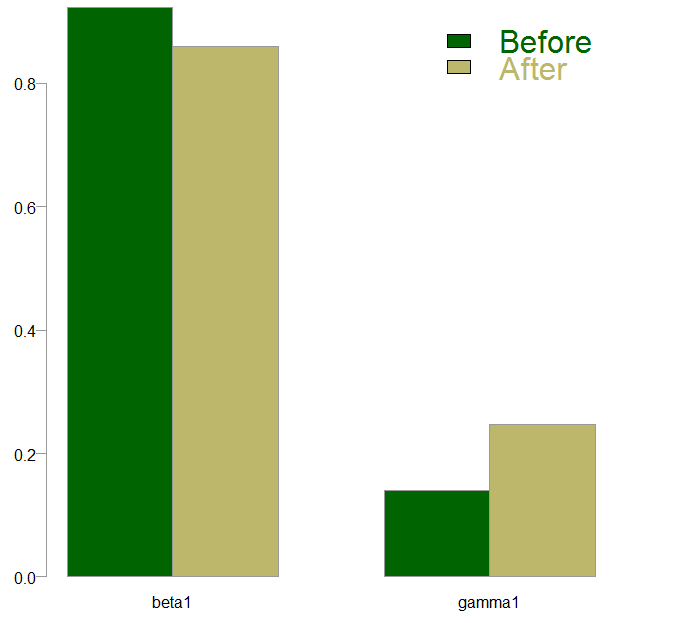
We see that the  estimate is positive for both periods, which means that on down days we have higher persistence than on up days. This fact is known in the literature as the leverage effect*. Post-crisis, the estimate for the
estimate is positive for both periods, which means that on down days we have higher persistence than on up days. This fact is known in the literature as the leverage effect*. Post-crisis, the estimate for the  parameter is slightly lower (less persistent process with respect to yesterday’s volatility) and the estimate is higher. My intuition is that the difference in the estimates of the parameter between the two periods does not warrant any further efforts (though you are welcome to do so). We can, however, check whether the difference in estimates, which looks quite substantial, is indeed large enough to be called significant.
parameter is slightly lower (less persistent process with respect to yesterday’s volatility) and the estimate is higher. My intuition is that the difference in the estimates of the parameter between the two periods does not warrant any further efforts (though you are welcome to do so). We can, however, check whether the difference in estimates, which looks quite substantial, is indeed large enough to be called significant.
Inference in Threshold-GARCH model
One way to make inference in these kind of models is using bootstrapping. Assume the daily returns are independent, a very weak assumption, and lets create the empirical distribution of the gamma parameter under the null hypothesis of no change. We can later see whether our estimate falls roughly in-line with where it should fall, given that no change had occurred.
Tgjrmodel_Before_gamma <- NULL # make room for the vector
for(i in 1:500){ # Sample 500 times
unifnum = sample(c(1:before_crisis), before_crisis, replace= T) # generate random index
# Save the resulting gamma1 parameter
Tgjrmodel_Before_gamma[i] = coef(ugarchfit(gjrtspec, ret[unifnum]))[6]
} # This takes a while
# ------------------------------------
# Now we plot the histogram along with critical values
# The green line is the after-crisis gamma estimate ---------
# ------------------------------------
hist(Tgjrmodel_Before_gamma, main="", xlab= "")
abline(v= quantile(Tgjrmodel_Before_gamma, .975), col= "darkred")
abline(v= quantile(Tgjrmodel_Before_gamma, .025), col= "darkred")
abline(v= coef(Tgjrmodel_After)[6], col= 3, lwd= 3)

What we did is to bootstrap the empirical distribution of the estimate. If there is no change, the estimate for post-crisis  should fall within the red lines. Those are the 97.5% and 2.5% quantiles. The green vertical line representing the estimate after the crisis, sits outside the upper boundary.
should fall within the red lines. Those are the 97.5% and 2.5% quantiles. The green vertical line representing the estimate after the crisis, sits outside the upper boundary.
This is a general technique and you can use it for whichever parameter you would like to test from whichever process.
Conclusion
We all know that volatility is time-varying. But here is some evidence that the model which generates the time-varying volatility forecasts\estimates is itself time varying. In the future, with more speed stemming from cloud and parallel computing, we would see more models which account for a parameter changes, even in those computationally-expensive volatility models.
Footnote
* If your long position goes in your favour, good for you. But if the position goes against you, posting more collateral may be in order, for that you may need to reduce your current position, or release cash from other positions. This arguably drags down equities further, if many participants are doing the same. The higher the leverage, the quicker the broker picks up the phone to make the margin call, hence the name.








Dear Eran,
Thank you for the interesting article.
Isn’t the point you raise already taken into account when using GARCH series to forecast market values? I would expect the new data points to be used to re-calculate the ARMA-GARCH model before any new operation, thus calculating a different beta and gamma every time. I am completely new to the field so this may not actually be the case, though.
Your question is quite common. The process is very responsive in that the most recent observation has a big impact. But, the parameters of the model are (typically) NOT re-estimated with each additional data point. As I mention above: it is not as computationally cheap as simple regression say. The process is estimated using the Maximum Likelihood method, and optimization is a must. To know more, have a look at this introductory book by Peter Christoffersen.
Dear Eran, I really like your blog and have learned a lot from it. This post is very instructive about regime switching GARCH model. However, I am not sure how to perform regime switching GARCH modelling when the transition probabilities are the function of one or two economic variables in R or in any other software. Any help is highly appreciated. Thank you.
Hi Eran, I am curious to know how to test for the performance of the regime switching model out-of-sample. I suspect the ‘complicated’ models like regime switching might overfit the data.
I suspect the same.. 🙂