The term ‘curse of dimensionality’ is now standard in advanced statistical courses, and refers to the disproportional increase in data which is needed to allow only slightly more complex models. This is true in high-dimensional settings. Here is an illustration of the ‘Curse of dimensionality’ in action.
‘Curse of dimensionality’ illustration; Value at risk estimation
There has been a tremendous and gratifying advances in the estimation of Value-at-Risk (VaR). Loosely speaking, this value is a lower-bound. With some probability, say 10%, and helped by some assumptions, you will lose no more than that particular value. For a single name in the portfolio, estimating a 10% VaR is fairly easy to do. What is important is that you have enough data for your estimate to be accurate. Specifically, it is crucial to have enough data points in that region- the 10% tail. The following figure shows the daily return distribution of US stocks (ticker SPY) and US bonds (ticker TLT). The blue bars represent points which lay in the 10% tail. Your VaR estimate relies heavily on those data points.
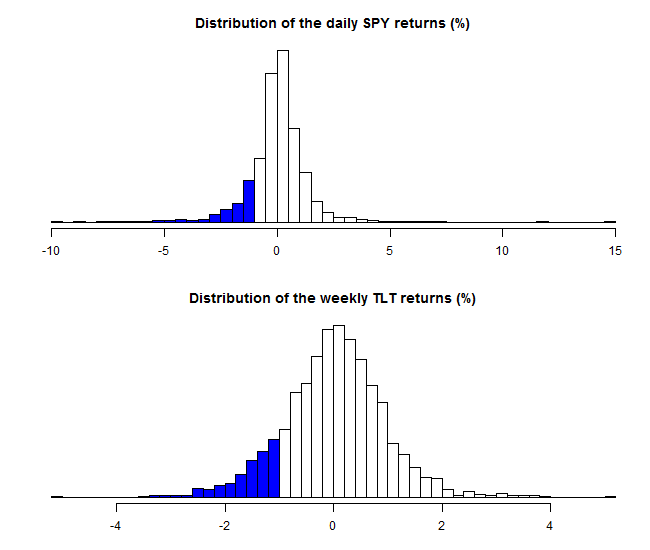
For 10 years of daily data we have 290 data points for SPY and 252 data points for TLT. A fair number, sure. Enough so that we can trust our VaR estimate (whichever you wish to estimate it).
Now, a lot of effort is flowing into the estimation of dependence in general, and specifically tail-dependence. You absolutely do not want your your bonds to fail you exactly when you rely the most on their protection\diversification. If there IS a strong tail dependence between stocks and bonds you need to find other instruments to defend your portfolio from tail event in stocks. But if tail-dependence is weak, really weak, not estimated to be weak, then you are good.
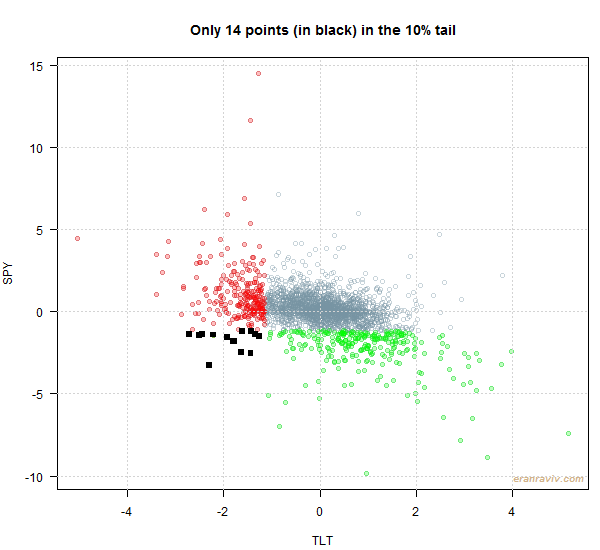
In the same spirit as for the (univariate) VaR estimation, for tail-dependence estimation you need enough data points so that you can estimate it reliably. Unlike the univariate case (VaR), now in the multivariate case, you need to have enough data points sitting elegantly in the 10% tail, but in the two dimensional space.
In the multivariate case much less of those around. See for yourself:
library(quantmod)
k <- 10 # how many years back?
end<- format(Sys.Date(),"%Y-%m-%d")
start<-format(Sys.Date() - (k*365),"%Y-%m-%d")
symetf = c('TLT', 'SPY')
l <- length(symetf)
w0 <- NULL
for (i in 1:l){
dat0 = getSymbols(symetf[i], src="yahoo", from=start, to=end, auto.assign = F,
warnings = FALSE,symbol.lookup = F)
w1 <-dailyReturn(dat0)
w0 <- cbind(w0,w1)
}
w0 <- 100*w0 # more to percentage points
colnames(w0) <- symetf
matplot(w0, ty= "l")
TT <- dim(w0)[1] # around observations
# how many in the left 10%
tail_obs_spy <- ifelse(w0[,"SPY"] < quan, 1, 0)
tail_obs_tlt <- ifelse(w0[,"TLT"] < quan, 1, 0)
sum(tail_obs_spy)
#[1] 290
sum(tail_obs_tlt)
#[1] 252
#-------------------------------------------------
jointt <- ifelse(tail_obs_tlt==1 & tail_obs_spy==1, 1, 0)
sum(jointt)
#[1] 14
Only 14.
Quick calculation: if you would like to have roughly the same amount of data points comparable to what you had in the univariate case you need not 10 years of data, but ~180 years (250/14).
So estimating tail-dependence between say 4 variables, defining the tail as 5%... you need A LOT of data, otherwise 'good luck to you sir', estimation is just too fragile.
A classic text-book 'curse of dimensionality' figure and app
This practical example hints to a common picture typically shown whenever 'curse of dimensionality' is discussed (taken from newsnshit):
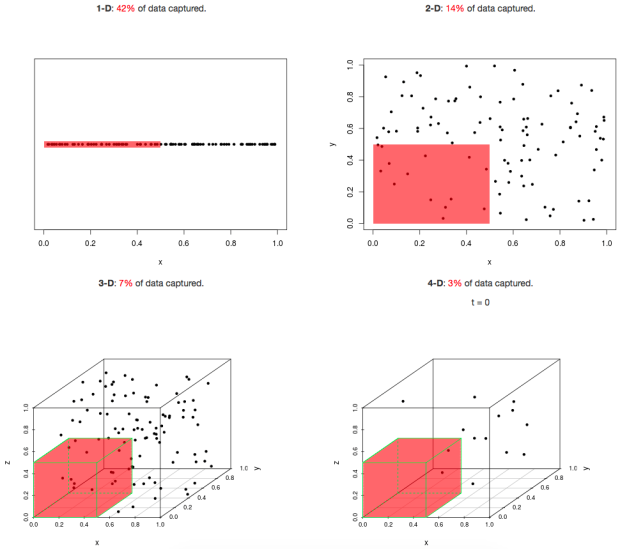
You can see that the number of data points that are captured by some fixed 'length' (in our previous example this is equivalent to the 10%) is rapidly diminishing as the dimension increases.
For a more interactive feel, where you can set your own 'length', check an shiny-app created by the guys from simplystatistics.
Code for (own) figures
# First figure
h <- hist(w0[,"SPY"], breaks=44, plot=F)
quan <- quantile(w0[,"SPY"], 0.1)
clr <- ifelse(h$breaks < quan, "blue", "white")
plot(h, col=clr, ylab= "", xlab= "", main= "Distribution of the daily SPY returns (%)", yaxt="n")
h <- hist(w0[,"TLT"], breaks=44, plot=F)
quan <- quantile(w0[,"TLT"], 0.1)
clr <- ifelse(h$breaks < quan, "blue", "white")
plot(h, col=clr, ylab= "", xlab= "", main= "Distribution of the weekly TLT returns (%)", yaxt="n")
# Second figure
plot(as.numeric(w0[,"SPY"]) ~ as.numeric(w0[,"TLT"]), xlab= "TLT", ylab= "SPY",
col= rgb(118/255, 147/255, 162/255, alpha = 0.4))
points(as.numeric(w0[tail_obs_tlt==1,"SPY"]) ~ as.numeric(w0[tail_obs_tlt==1,"TLT"]), xlab= "TLT", ylab= "SPY",
col= transcol[3], cex=1, pch=19)
points(as.numeric(w0[tail_obs_spy==1,"SPY"]) ~ as.numeric(w0[tail_obs_spy==1,"TLT"]), xlab= "TLT", ylab= "SPY",
col= transcol[2], cex=1, pch=19)
points(as.numeric(w0[jointt==1,"SPY"]) ~ as.numeric(w0[jointt==1,"TLT"]), xlab= "TLT", ylab= "SPY",
col= 1, cex=1.1, pch= 15)
title("Only 14 points (in black) in the 10% tail")








One comment on “Curse of dimensionality part 1: Value at Risk”