While linear correlation (aka Pearson correlation) is by far the most common type of dependence measure there are few arguably better ways to characterize\estimate the degree of dependence between variables. This is a fascinating topic I keep coming back to. There is so much for a typical geek to appreciate: non-linear dependencies, should we consider the noise in the data or rather just focus on the underlying process, should we consider the whole distribution or just few moments.
In this post number 6 on correlation and correlation structure I share another dependency measure called “distance correlation”. It has been around for a while now (2009, see references). I provide just the intuition, since the math has little to do with the way distance correlation is computed, but rather with the theoretical justification for its practical legitimacy.
Denote  as the distance correlation. The following is taken directly from the paper Brownian distance covariance (open access) :
as the distance correlation. The following is taken directly from the paper Brownian distance covariance (open access) :
Our proposed distance correlation represents an entirely new approach. For all distributions with finite first moments, distance correlation R generalizes the idea of correlation in at least two fundamental ways:
characterizes independence of X and Y.
The first point is super useful and far from trivial. You can theoretically calculate distance correlation between two vectors of different lengths (e.g. 12 monthly rates and 250 daily prices)*. The second is a must-have for any aspiring dependence measure. While linear correlation be computed to be very small number even if the vectors are dependent or even strongly dependent (quite easily mind you), distance correlation is general enough so that when it’s close to zero, then the vectors must be totally independent (linearly and non-linearly).
Although they don’t present it like this in the paper, the idea is a simple functional extension of a usual probabilistic fact: if two random variables are independent then
![\[P(X=a \text { and } Y=b)=P(X=a) \cdot P(Y=b)\]](https://eranraviv.com/wp-content/ql-cache/quicklatex.com-7834c460ee45ff5b72d4619adc5b719f_l3.svg "Rendered by QuickLaTeX.com")
Now instead of thinking about variables, think about X and Y as functions (in the paper they use characteristic functions), X and Y are independent if and only if
![\[f_{X, Y}=f_{X} f_{Y}\]](https://eranraviv.com/wp-content/ql-cache/quicklatex.com-1d0c935365d5d7653bbbc7dbb8818cd9_l3.svg "Rendered by QuickLaTeX.com")
Now you can quantify how far the joint function  is from the product of the two individual functions
is from the product of the two individual functions  . If they are identical, the distance will be zero. Use the complement [1 – 0] to get a measure that returns 1 for full dependency and 0 for complete independence. It’s a bit like saying the following: if
. If they are identical, the distance will be zero. Use the complement [1 – 0] to get a measure that returns 1 for full dependency and 0 for complete independence. It’s a bit like saying the following: if  , and
, and  while if they are independent I expect
while if they are independent I expect  (
( ), then
), then  is my measure for how dependent are those random variables. Informally speaking we can say we compute some sort of “excess dependency over the fully independent case”. We have seen this idea before talking about asymmetric correlations of equity portfolios.
is my measure for how dependent are those random variables. Informally speaking we can say we compute some sort of “excess dependency over the fully independent case”. We have seen this idea before talking about asymmetric correlations of equity portfolios.
I replicated figure (1) from the previous post on this topic and I add the distance correlation measure (denoted here as  ) for comparison. Afterwards we can say a few words about advantages or disadvantages.
) for comparison. Afterwards we can say a few words about advantages or disadvantages.
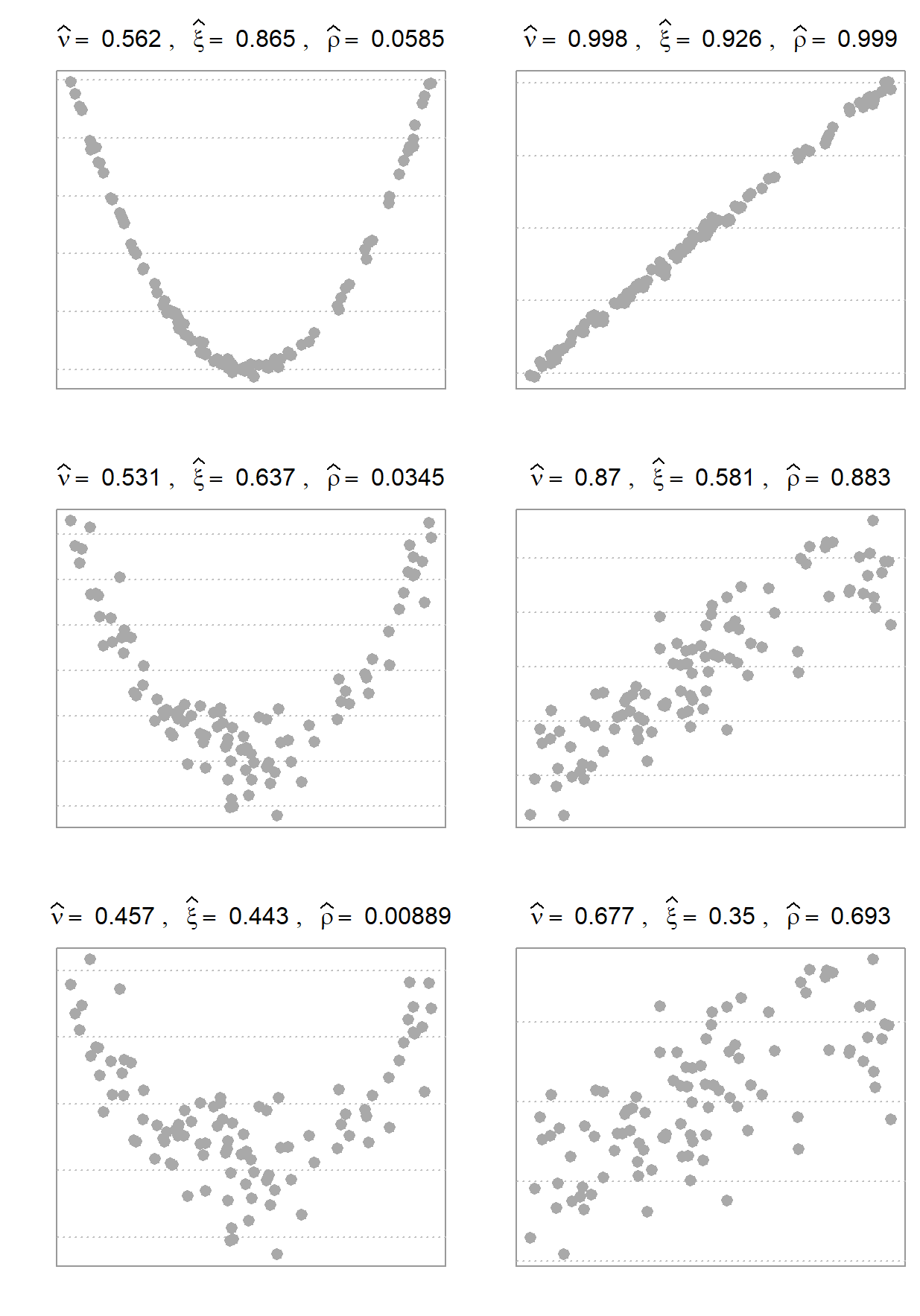
denotes distance correlation,  denotes the “new coefficient of correlation” (as they dub it in the original paper), and
denotes the “new coefficient of correlation” (as they dub it in the original paper), and  denotes the usual Pearson correlation. Distance correlation measure relies on the characteristic functions of the realized vectors (think simply their probability distribution). Therefore it cares about the profile of dependence, rather than the strength of dependence; which is the main takeaway from the figure. By way of contrast you see that “new coefficient of correlation” dramatically decreases (from top to bottom) as noise being added to the data. Distance correlation is less sensitive to that. The following figure offers some clarity, I hope:
denotes the usual Pearson correlation. Distance correlation measure relies on the characteristic functions of the realized vectors (think simply their probability distribution). Therefore it cares about the profile of dependence, rather than the strength of dependence; which is the main takeaway from the figure. By way of contrast you see that “new coefficient of correlation” dramatically decreases (from top to bottom) as noise being added to the data. Distance correlation is less sensitive to that. The following figure offers some clarity, I hope:
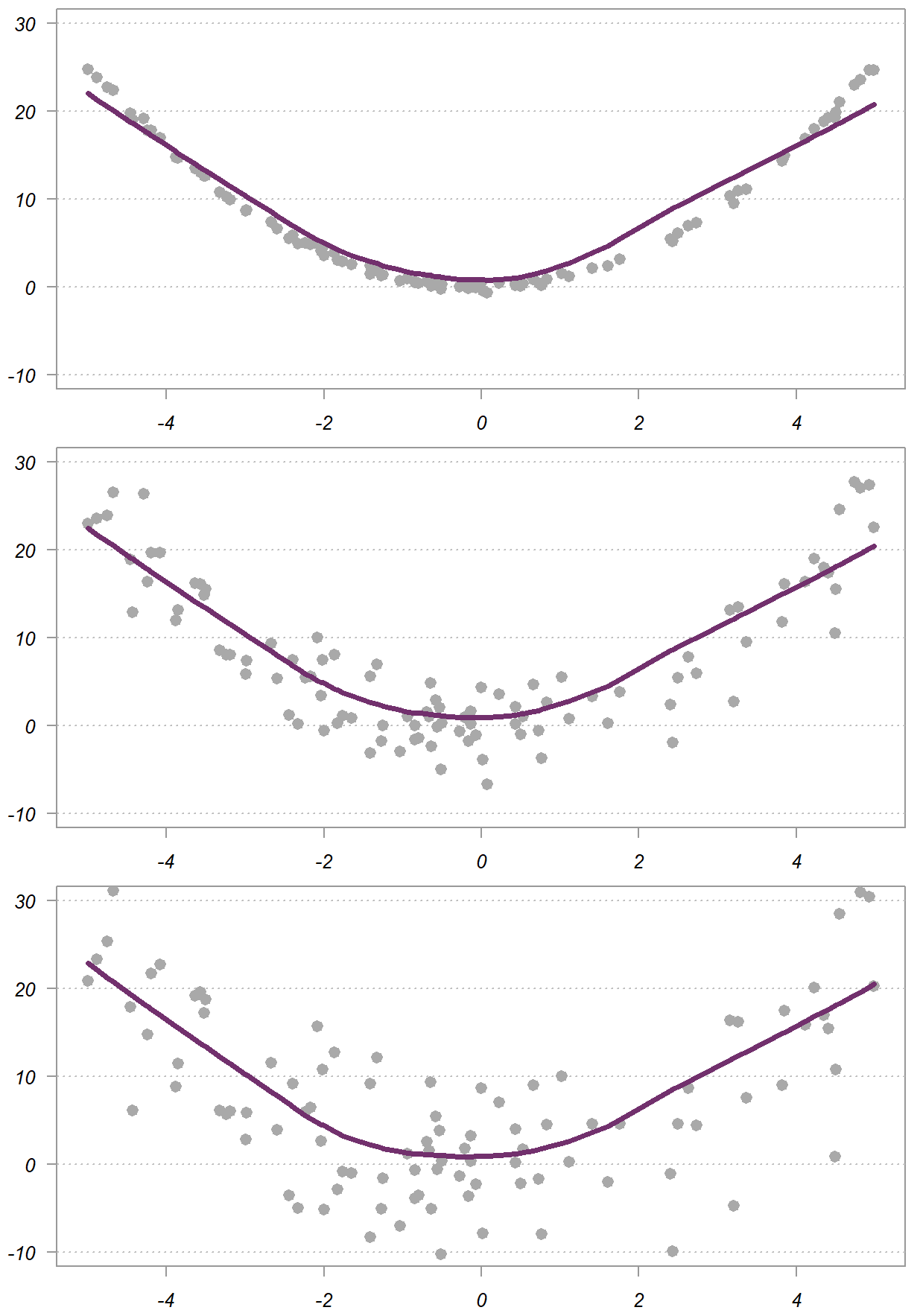
Regardless of the added noise – from top to bottom in the figure, the relation between the two variables x and y, depicted using the purple smooth line, is very similar. The dependency value for the  measure is decidedly decreasing as noise being added, because it also considers the noise in the data, while distance correlation focuses on the underlying dependency structure, only.
measure is decidedly decreasing as noise being added, because it also considers the noise in the data, while distance correlation focuses on the underlying dependency structure, only.
So, you decided to use a dependency measure that captures both linear and non-linear dependence.
Should you then use , or  ?
?
It’s a matter of preference.
If the empirical realization is what matters to you – meaning you would like to account for the noise in the data, the measure is the way to go. If what you care about is the underlying “skeleton profile” then you should opt for using distance covariance\correlation.
Correlation between stocks and bonds, again..
Correlation between stocks and bonds is an interesting case in point. These two are undoubtedly correlated, but with a complicated dependence structure which has to do with the economy and anticipated actions by central banks. Let’s see what the three dependency measure report for two relevant tickers: TLT (long term US bong ETF) and SPY (S&P 500 ETF). I also plot an estimated smoother for the two time series (in green).
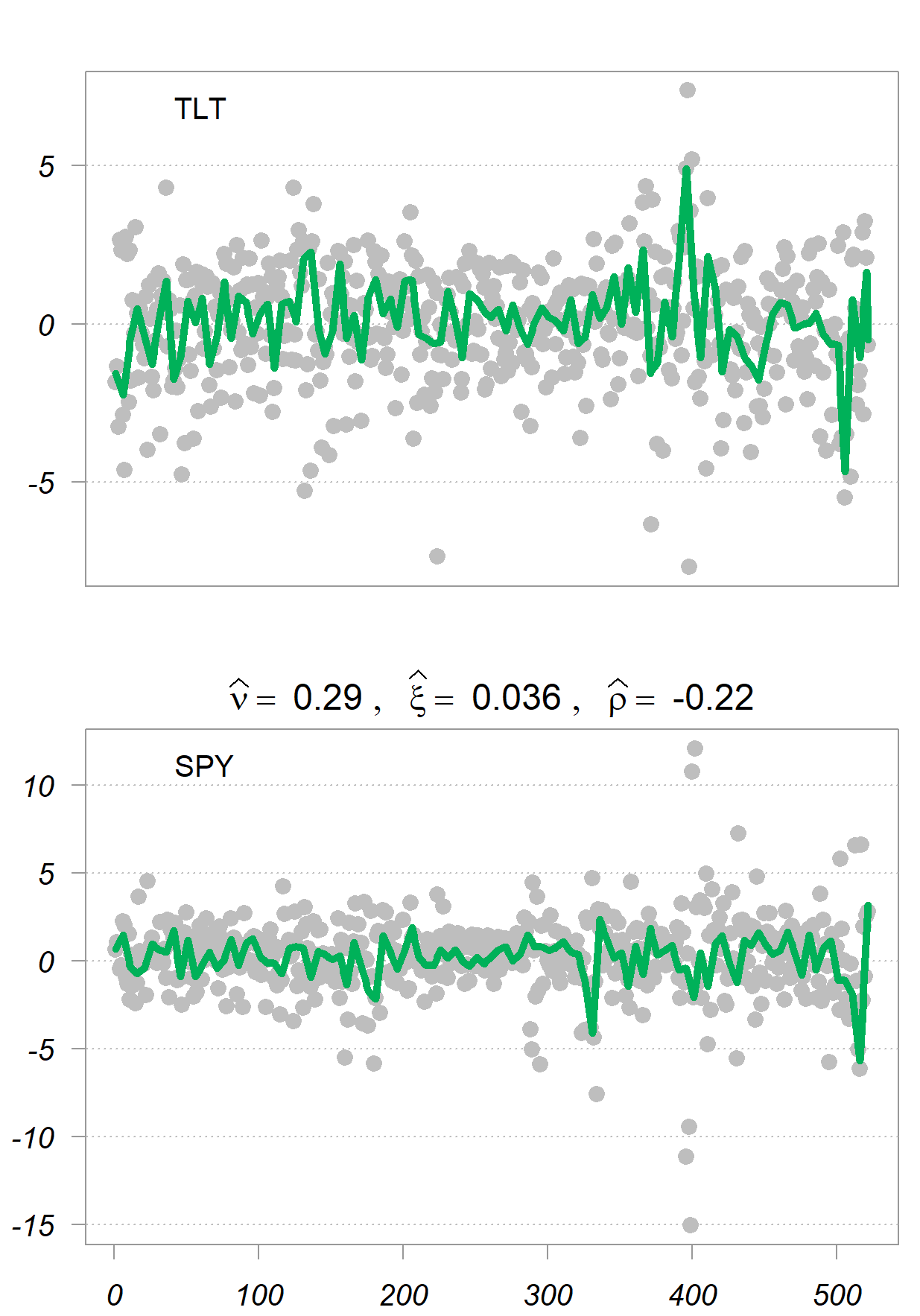
Interesting stuff. We observe that:
is negative, which makes sense on the whole. is close to zero given that the return series are super noisyYou may wonder about the sign, but remember that both and distance correlation are tailored to capture also non-linear dependencies, which makes the sign irrelevant (they both range between 0 and 1).
References
Footnotes
* That said, I only found implementations that allow for equal vector length. But you can code it if you need.








Super interesting read! From the concluding figure, one could say that the question of whether to use the “new coefficient of correlation” or the distance correlation boils down to the amount of noise in the data. If the former is close to 0, it seems worthwhile to check whether the latter one is 0 as well. If it is not, then there might actually be some dependence between the variables, but the noise is concealing it from the “new coefficient of correlation”.