This post is about the concept of entropy in the context of information-theory. Where does the term entropy comes from? What does it actually mean? And how does it clash with the notion of robustness?
Category: Statistics and Econometrics
What is a Latent Variable?
This post provides an intuitive explanation for the term Latent Variable.
Most popular machine learning R packages – part 2
In a previous post: Most popular machine learning R packages, trying to hash out what are the most frequently used machine learning packages, I simply chose few names from my own memory. However, there is a CRAN task views web page which “aims to provide some guidance which packages on CRAN are relevant for tasks related to a certain topic.” So instead of relying on my own experience, in this post I correct for the bias by simply looking at the topic
Machine Learning & Statistical Learning. There are currently around 100 of those packages on CRAN.
Create own Recession Indicator using Mixture Models
Context
Broadly speaking, we can classify financial markets conditions into two categories: Bull and Bear. The first is a “todo bien” market, tranquil and generally upward sloping. The second describes a market with a downturn trend, usually more volatile. It is thought that those bull\bear terms originate from the way those animals supposedly attack. Bull thrusts its horns up while a bear swipe its paws down. At any given moment, we can only guess the state in which we are in, there is no way of telling really; simply because those two states don’t have a uniformly exact definitions. So basically we never actually observe a membership of an observation. In this post we are going to use (finite) mixture models to try and assign daily equity returns to their bull\bear subgroups. It is essentially an unsupervised clustering exercise. We will create our own recession indicator to help us quantify if the equity market is contracting or not. We use minimal inputs, nothing but equity return data. Starting with a short description of Finite Mixture Models and moving on to give a hands-on practical example.
Test of Equality Between Two Densities
Are returns this year actually different than what can be expected from a typical year? Is the variance actually different than what can be expected from a typical year? Those are fairly light, easy to answer questions. We can use tests for equality of means or equality of variances.
But how about the following question:
is the profile\behavior of returns this year different than what can be expected in a typical year?
This is a more general and important question, since it encompasses all moments and tail behavior. And it is not as trivial to answer.
In this post I am scratching an itch I had since I wrote Understanding Kullback – Leibler Divergence. In the Kullback – Leibler Divergence post we saw how to quantify the difference between densities, exemplified using SPY return density per year. Once I was done with that post I was thinking there must be a way to test the difference formally, rather than just quantify, visualize and eyeball. And indeed there is. This post aim is to show to formally test for equality between densities.
Orthogonality in Statistics
Orthogonality in mathematics
The word Orthogonality originates from a combination of two words in ancient Greek: orthos (upright), and gonia (angle). It has a geometrical meaning. It means two lines create a 90 degrees angle between them. So one line is perpendicular to the other line. Like so:
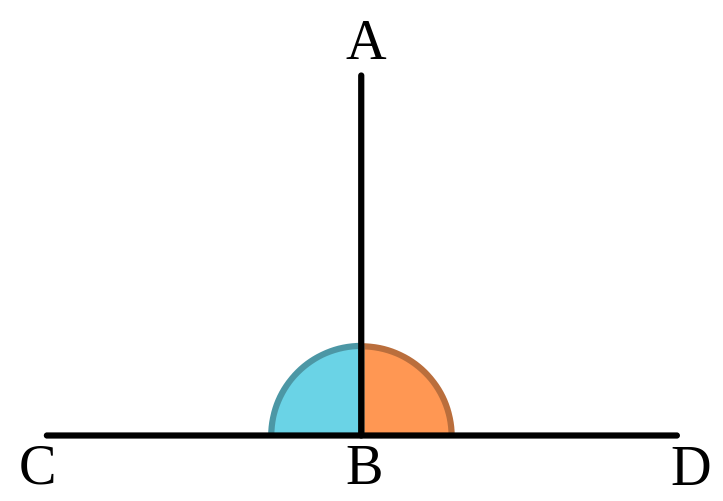
Even though Orthogonality is a geometrical term, it appears very often in statistics. You probably know that in a statistical context orthogonality means uncorrelated, or linearly independent. But why?
Why use a geometrical term to describe a statistical relation between random variables? By extension, why does the word angle appears in the incredibly common regression method least-angle regression (LARS)? Enough losing sleep over it (as you undoubtedly do), an extensive answer below.
Kaggle Experience
At least in part, a typical data-scientist is busy with forecasting and prediction. Kaggle is a platform which hosts a slew of competitions. Those who have the time, energy and know-how to combat real-life problems, are huddling together to test their talent. I highly recommend this experience. A side effect of tackling actual problems (rather than those which appear in textbooks), is that most of the time you are not at all enjoying new wonderful insights or exploring fascinating unfamiliar, ground-breaking algos. Rather, you are handling\wrangling\manipulating data, which is.. ugly and boring, but necessary and useful.
I tried my powers few years ago, and again about 6 months ago in one of those competitions called Toxic Comment Classification Challenge. Here are my thoughts on that short experience and some insight from scraping the results of that competition.
R in Finance highlights
The yearly R in Finance conference is one of my favorites:
Curse of dimensionality part 3: Higher-Order Comoments
Higher moments such as Skewness and Kurtosis are not as explored as they should be.
These moments are crucial for managing portfolio risk. At least as important as volatility, if not more. Skewness relates to asymmetry risk and Kurtosis relates to tail risk.
Despite their great importance, those higher moments enjoy only a small portion of attention compared with their lower more friendly moments: the mean and the variance. In my opinion, one reason for this may be the impossibility of estimating those moments, estimating them accurately that is.
It is yet another situation where Curse of Dimensonality rears its enchanting head (and an idea for a post is born..).
Understanding Kullback – Leibler Divergence
It is easy to measure distance between two points. But what about measuring distance between two distributions? Good question. Long answer. Welcome the Kullback – Leibler Divergence measure.
The motivation for thinking about the Kullback – Leibler Divergence measure is that you can pick up questions such as: “how different was the behavior of the stock market this year compared with the average behavior?”. This is a rather different question than the trivial “how was the return this year compared to the average return?”.
LASSO, LASSO, LASSO
LASSO stands for Least Absolute Shrinkage and Selection Operator. It was first introduced 21 years ago by Robert Tibshirani (Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society. Series B). In 2004 the four statistical masters: Efron, Hastie, Johnstone and Tibshirani joined together to write the paper Least angle regression published in the Annals of statistics. It is that paper that sent the LASSO to the podium. The reason? they removed a computational barrier. Armed with a new ingenious geometric interpretation, they presented an algorithm for solving the LASSO problem. The algorithm is as simple as solving an OLS problem, and with computer code to accompany their paper, the LASSO was set for its liftoff*.
The LASSO overall reduces model complexity. It does this by completely excluding some variables, using only a subset of the original potential explanatory variables. Since this can add to the story of the model, the reduction in complexity is a desired property. Clarity of authors’ exposition and well rehashed computer code are further reasons for the fully justified, full fledged LASSO flareup.
This is not a LASSO tutorial. Google-search results, undoubtedly refined over years of increased popularity, are clear enough by now. Also, if you are still reading this I imagine you already know what is the LASSO and how it works. To continue from this point, what follows is a selective list of milestones from the academic literature- some theoretical and practical extensions.
Density Estimation Using Regression
Density estimation using regression? Yes we can!
I like regression. It is one of those simple yet powerful statistical methods. You always know exactly what you are doing. This post is about density estimation, and how to get an estimate of the density using (Poisson) regression.
Computer Age Statistical Inference – now free
If you consider yourself Econometrician\Statistician or one of those numerous buzz word synonyms that are floating around these days, Computer Age Statistical Inference: Algorithms, Evidence and Data Science by Bradley Efron and Trevor Hastie is a book you can’t miss, and now nor should you. You can download the book for free.
My first inclination is to deliver an unequivocal recommendation. But in truth, my praises would probably fall short of what was already written.
So what can I give you? I can say that there are currently 6 amazon reviews, with a 4.5 average. One of the reviewers writes that there is some overlap with previous work. I agree. But it doesn’t matter. It reads so well, call it a refresher. Let’s face it, it is not as if you always have it so clear in your head such that you can afford to skip sections because you read something similar before.
I can also tell you why I think it is a special book.
Statistical Shrinkage
Shrinkage in statistics has increased in popularity over the decades. Now statistical shrinkage is commonplace, explicitly or implicitly.
But when is it that we need to make use of shrinkage? At least partly it depends on signal-to-noise ratio.
Top countries in poker (Test equality of proportions using bootstrap)
Machine-estimated reading time: [est_time]
Every once in a while I play poker online. The poker site allows you to ask for tournament history. You get an email which contains hundreds summaries (I open several tables at once so have quite some history), a typical summary looks as follows: